
There has been some amount of discussion about segment size, triangulation, and the number of cousins who can share a Triangulated Group. The discussion often uses terms like extremely rare, small segments, distant ancestors, etc. without using specific examples. The arguments go from it’s OK to triangulate with close relatives, to it’s virtually impossible with distant relatives – and there is no discussion of any middle ground. The odds do diminish as you go back in ancestry, but there is no artificial dividing line: closer works, distant doesn’t work. There are always a gradation – shades of gray, if you will. Let’s see if we can put boundaries on it.
In my mind, one way to try to see the forest, and the trees, is to really take a look at an average genome (23 chromosomes, 3 billion base pairs), and see what kind of segments we might see at each generational level. Most of us know that we get pretty large segments from our grandparents, and the size drops down with each generation as we work our way back/up our ancestry. So let’s develop a table and take it back and see what we have.
The average number of crossovers per generation is 34. Yes, the average for males (fathers) is 27, and the average for females (mothers) is 41 (per www.isogg.org/wiki/Recombination ). But this difference (with respect to the total number of crossovers in a genome) fades after just a few generations – so we’ll use the average, 34.
Crossover Points in One Generation
Let’s start with a parent and 23 pairs of chromosomes. In passing a genome to a child, this parent adds 34 crossovers, which results in 23+34 = 57 segments. Here is Figure 1 showing 34 crossovers and the 57 segments in one genome:

These are generally large segments from the grandparents. On average, these segments will be 3,400 cM divided by 57 segments or about 60cM per segment. But clearly some are larger and some are smaller. Sometimes a chromosome is passed intact – see Chr 21 above. You can try this at home, on a sheet of paper – just make 23 horizontal lines and put 34 vertical tic marks on them. You can put a few more or less tic marks, but the overall picture of relatively large segments from your grandparents will be the same.
The important observation here is that you have these ancestral segments on your chromosomes – they are fixed between fixed crossover points created when your parent passed these chromosomes to you. Of course you don’t know where they are at first, but as you determine Triangulated Groups (TGs) with various cousins, you’ll find that none of the shared segments span across one of these crossover points. And in fact, with enough shared segments you will start to see these crossover points firm up, with separate TGs (from the other grandparent) on either side of them. This chromosome mapping, with shared segments, identifies the crossover points for your ancestral segments. The shared segments with Matches usually only overlap part of your ancestral segment from a Common Ancestor – in this case a grandparent.
Crossover Points in Two Generations
Adding 34 tic marks per generation is a good exercise to carry out for several generations and get the feel for how this works. Let’s try another 34 vertical tic marks. We’ll add the tic marks to show the crossover points that were formed when grandparents passed the chromosomes (which they got from their parents) down to your parents. In effect this takes the 57 segments we had in Figure 1, and (with 34 more crossovers) creates 91 total segments as shown in the genome in Figure 2:

We still have fairly large segments. On average now, these ancestral segments are 3,400/91 = about 37cM per segment. Again – some will be larger, some smaller. Each of these segments in Figure 2 (between tic marks – both old and new) are from a great grandparent. These segments fill up each and every chromosome in this genome. You may note that some of the grandparent segments were not subdivided. This is not unusual. In fact it has to happen. We started with 57 ancestral segments and added 34 new tic marks (crossover points) – so 34 segments got subdivided and 23 segments did not.
Crossover Points for 13 Generations
In the next generation back, we would add 34 more new tic marks (crossovers) which would subdivide only 34 of the 91 ancestral segments creating a total of 125 ancestral segments from 2G grandparents, and leaving 57 segments untouched (no subdivision). Here is a table in Figure 3 carrying this math out for 13 generations:
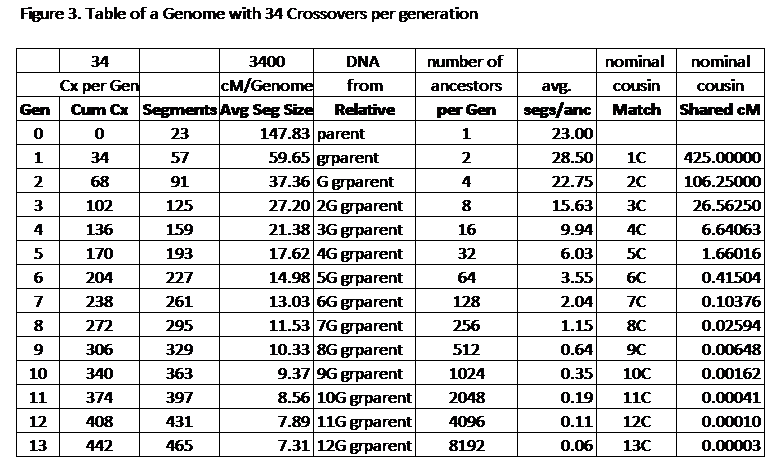
Discussion of Figure 3:
Note: This is a table with various values, depending on which generation you are focused on. So successively, pretend you are at a particular generation and read across to see the statistics. Cousins are abbreviated: 2nd cousin is 2C; 2nd cousin once removed is 2C1R.
– Gen 0: You have 23 chromosomes from a parent (we are only working on one genome, so the number of ancestors is 1. Your parent gave you 23 very large segments (which are chromosomes)
– Gen 1: You get DNA contributions from your 2 grandparents. This is in 57 segments spread over one genome. At this level of your ancestry you would see Matches with 1Cs. Review this in Figure 1.
– Gen 2: You get DNA contributions from your 4 Great grandparents on one side. Now you have 91 ancestral segments spread over 23 chromosomes, and each segment averages about 37cM. Some of these ancestral segments are larger, and some are smaller; and they all add up to 23 complete chromosomes (one full genome). This is the generation that you usually share with 2Cs – review Figure 2. In Figure 3 I also show the calculated shared segment values for the various cousins. With a 2C, you would normally share a total of 106cM (from one side). But the average size of the segments from the Great grandparents is only 37cM. This reflects the fact that you will probably share multiple segments with a 2C – perhaps on average three 37cM segments totaling 111cM… Remember these are averages and in actual practice there is a LOT of variation.
-Gen 3: This shows an average ancestral segment size of 27cM from your 2G grandparents – spread over 125 total segments. The total shared segment for a particular 3C is about 27cM – so you might expect a single segment from a 3C (again, this is just an average, but it might reflect what you often see). I’ve underlined ancestral segment (what you actually got from an ancestor), and shared segment which is the overlap between you and a Match. This overlap is rarely exactly the same ancestral segment in both you and your Match – one or both of you probably has somewhat more in the full segment you got from the Common Ancestor.
NB: this overlapping (shared) segment vs ancestral segment difference may be the root cause of some math calculations which have been touted as proving that exact matches among more than 3C are very rare. Several cousins having the exact same ancestral segment may be fairly rare, but experience with Triangulated Groups shows that overlaps are not that rare.
-Gen 4: Ancestral segments (averaging 21 cM) from your 16 3G grandparents are spread over about 159 segments. So you would see, on average, an ancestral segment from each 3G grandparent in roughly different 10 segments spread over the chromosomes in that genome. Most of your Matches would be 4C (or 3C1R or 4C1R). The shared segments would average 6.6cM, but another way to look at this is that roughly half of them would be over 7cM. However, experience shows that a relatively small percentage of our Matches are 4C and closer relatives. So there are not many such Matches to cover all the segments in our genome.
-Gen 5: Our 32 4G grandparents still give us fairly large 17cM ancestral segments (on average) spread out over 193 segments. We would still see most of our 4G grandparents in multiple segments. Our 5C Matches only share, on average, 1.7cM. So only some of them, on the tails of the distribution curves, will share 7cM or more. The offset is that we have so many 5Cs, that we still get plenty of IBD matches with them. However, the key point here is that while we may have a 17cM ancestral segment from a 4G grandparent, a 5C is only likely to share part of that with us. It would take several 5Cs, each with a 7-10cM segment, partially overlapping our own ancestral segment, to “cover” our 17cM ancestral segment. In practice we often get 5C Matches with above average segments, but usually not as large as 17cM.
-Gen 6: Our 64 5G grandparents pass down ancestral segments to us that average about 15cM. They pass these down to an average of 227 segments; and each 5G grandparent will pass down DNA to 3 or 4 different segments, on average. Perhaps some of our 5G grandparents won’t have DNA that reaches us at all, while others my pass down 5 or more segments – roughly, it usually averages out. At this level most of our Matches will be 6C, give or take a little. A 6C, on average, only shares 0.4cM of DNA with us. But there are long tails on these distribution curves, AND we have a LOT of 6Cs. The result is that we do have many 6C who do share IBD segments with us over 7cM. Yes, the probability of a specific 6C shared segment is one forth the probability of a 5C, but we have so many more 6C than 5C, we actually get more Matches with 6C. This means more 6C Matches are out there with a shared segment over 7cM, than there are for 5C. Again, it will normally take several of them to “cover” and ancestral segment (a TG).
-Gen 8: Skipping a generation to the 256 7G grandparents. At this point there are an average of 295 segments, or about one segment per 7G grandparent. Clearly by this time some of the 7G grandparents do not contribute to your DNA, and some 7G grandparents contribute to several ancestral segments. Your ancestral segments are in the 11-12cM range, on average. And despite the fact that 8Cs only share a small amount of DNA on average, there will still be many 8C with shared segments above a 7cM threshold.
Summary
All through this analysis, the number of ancestral segments has increased by a constant 34 with each generation; the average segment size starts off large and decreases with each generation, but even after 13 generation, the average ancestral segment is still over 7cM; the number of ancestors continues to double with each generation (and at some point duplicates will start to appear, but as I’ve outlined in Endogamy I and II, each duplicate really acts like a separate ancestor); and the average size of shared segments decreases by a factor of 4 with each generation, but we still see many Matches with shared segments over 7cM. To expand on this last point, I have over 10,400 “phased” Matches at AncestryDNA, with all the pile-ups and IBS already culled out. About 400 of these Matches are 4C or closer, leaving over 10,000 Matches in the 5C or more distant range. The distribution of these is spread out among 5C, 6C, 7C, 8C, etc. It is, so far, unclear how far back these go, but clearly there are many in the 5C-8C range. And AncestryDNA claims their “phasing” program has less than a 1% error rate. So 99% of these are IBD shared segments, probably most in the 6C-to-8C range. To my thinking, this means most of them must line up somewhere on our chromosomes. If we assume half, or 5,000, of these Matches are for each genome, on average, then these 5,000 Matches must be on 300 to 400 of my ancestral segments – or over 10 Matches in the 5C-8C range on every segment, on average. Some ancestral segments (TGs) may have more, some may have less, but the 5,000 IBD Matches have to go somewhere. I’ve picked on AncestryDNA here, because they poo-poo Triangulation (I think they don’t really understand it), and because they have equations that some have used to argue that we cannot have multiple 4C or above in TGs. But the same analysis is true using 23andMe and FTDNA data – they each report many Matches, they each claim a small IBS rate (under 5%), and by their own estimates, most of our Matches are beyond 4C. All of these IBD Matches have to be on our chromosomes somewhere. And, in 14 months (by my estimation), we will have twice as many Matches as we have now – we’ll have over 20 Matches per ancestral segment (TG)!
NOTE: the number of crossovers per generation will average out. So the number of segments created by each generation is fairly accurate – there is much less variation in these numbers than you might find in the average cM for an ancestral segment (which has a somewhat wider range) or a shared segment (which appears to have a much wider range).
“the main thing is to keep the main thing the main thing”
- Your genome (chromosomes) is divided into segments by crossover points.
- These are your ancestral segments, and each one is from a specific ancestor.
- Each Match will have his/her own crossover points and ancestral segments from specific ancestors.
- When you share an IBD segment with a Match this segment comes from a Common Ancestor (CA).
- A shared segment means your ancestral segment and your Match’s ancestral segment overlap.
- Your Match may have a small ancestral segment, which falls within your ancestral segment; a large ancestral segment, which includes your ancestral segment; or, usually, any size ancestral segment which overlaps a portion of your ancestral segment.
- The overlapping amount may be relatively small (say 7cM), or as large as your ancestral segment.
- The odds are very small that you and a Match would get exactly the same segment from a CA. And certainly the odds would be extremely small that you and several Matches would get exactly the same ancestral segment from a Common Ancestor.
- However, from the numbers of IBD shared segments we are getting from Matches, compared to the number of ancestral segments, it is highly probable that multiple Matches can and do have ancestral segments which overlap your ancestral segments.
Note: A full Triangulated Group (TG) is equivalent to one of your ancestral segments. Which ancestral segment the TG represents depends on the shared (overlapping) segments you have with your Matches. Several Matches with overlapping segments in a TG will tend to “wall paper” your ancestral segment – with enough of the right Match/segments your TG will cover the whole ancestral segment. Some TGs may be from a closer ancestor (say a great grandparent), some may be somewhat more distant (say a 7G grandparent). From my experience, most TGs will be in the 10-40cM range. This does create a hodge-podge effect (with TGs from different generations), but the TGs tend to be adjacent to each other from one end of each chromosome to the other. Alternatively, you can try to map to a specific generation – perhaps starting with grandparents (and determine those crossovers), and then determine which of those segments are subdivided into smaller segments from the great grandparents, and which segments remain intact going back that one generation. And then continue in this fashion with each additional generation. The drawback to this process is that you need many close relatives to take DNA tests to determine all the crossover points at each generation.
A final word of caution: don’t get too lost in the details or the math. Generally, you will have many Matches and IBD segments. Because they are IBD segments, they have to go somewhere on Mom’s side or Dad’s side. 23andMe and FTDNA have developed algorithms to help insure that most of your Match segments over 7cM are IBD, and from experience we know that almost all of the shared segments over 10cM are IBD, and well over half of the 7-10cM segments are IBD. So if you are reading this blog, you are probably into utilizing segments, along with your genealogy, to improve your family Tree. You should also upload to GEDmatch to find other Matches (from all 3 testing companies) with segments. When segments over 7cM Triangulate, it’s a very strong indication that those segments are IBD and the resulting TGs are from a Common Ancestor. You have an ancestral segment at the location of each TG, and your Matches share part of that ancestral segment with you. Each ancestral segment (TG) came from one of your parents and one of your grandparents, etc. Match/segments in that TG have to come from a distant ancestor who is ancestral to that grandparent. There is no cutoff to this process. We cannot say that only our large ancestral segments are valid. All of our ancestral segments came from a specific ancestor. Our ancestral segments have their own ancestral “Tree”. You may be more confident about a TG including a first or second cousin, but you probably don’t have enough tested cousins to cover every TG over all of your chromosomes. That doesn’t mean these other TGs are not valid, it just means you don’t have a close cousin to validate it. You have to use the closest cousin you can find to validate each TG. Your ancestral segments are real! They are part of you, from your ancestors. And Matches who share those segments, also share their ancestry – no matter how far back the Common Ancestor is. Note from Figure 1 and 2 that segments from more distant ancestors are “nested” within larger segments from closer ancestors. So if you cannot determine the most distant Common Ancestor, look for the closer Common Ancestor who provided the larger ancestral segment.
05D Segment-ology: Crossovers by Generation by Jim Bartlett 21060201

Jim, This post has been extremely helpful! However, I am still trying to get my mind around the implications. I wonder if you would consider the following problem and tell me if I am understanding this correctly. (Although I’m not sure if I am describing it in a way that makes complete sense!)
I have been working on identifying the ancestors of one pair of my 4th-great grandparents, ahnentafel #0068/0069. At the moment I am focusing on a particular segment on chromosome 19 that I seem to have inherited from #0068/0069.
I am of course descended #0034, who is a child of #0068/0069. Match X is a 4th cousin, 1x removed, who is descended from a second child of #0068/0069. Match Y is a 4th cousin, 1x removed, who is descended from a third child of #0068/0069.
On GEDmatch, cousins X and Y both match with me on segments of slightly different length (36 and 31 cM), but both have the same starting point of 1,341,509. On MyHeritage, the same testers also match with me at a similar range of cMs with a common starting point, but the value of that starting point is slightly different: 1,396,462. On both GEDmatch and MyHeritage, several close relatives of X and Y also match on segments with the exact same starting point.
Question 1: Does this mean, then, that the starting point of these shared segments likely represents a Crossover that occurred somewhere in my own ancestry in the line between me and my 3rd GG #0034?
Next question: there is a triangulated 13.6 cM match on GEDmatch between me, cousins X and Y, and tester Z. For me, cousin X, and cousin Y, the beginning and end points of our matching segment with tester Z are all *exactly the same*: 3,432,252 and 8,159,362.
Am I correct to assume, then, that this segment must have been inherited from someone ancestral to either 0068 or 0069?
Further, am I correct to surmise that the common ancestor with tester Z must be *several* generations previous to 0068 or 0069?
LikeLike
Jesse – great questions.
First – In a Triangulated Group of segments… all of the shared segments match a segment of *your* DNA – which is a segment from *your* Ancestor. There is a fixed start and end point for *your* DNA segment – although it may be a little fuzzy on either end because there is no hard “signpost” in our DNA that says where the Ancestor segments start and stop. In general, each Match got their own segment from the same Ancestor – it’s very rare to get exactly the same. BUT… the only thing you will see in a *shared* segment is the overlap with you. So it may appear that some Matches have the same start and/or the same end locations, that is not a requirement – the requirement is that it cannot be before or after your segment.
Q1: Yes – that’s a likely crossover point.
Q2: Well – maybe the it came from 0068 or 0069 or any of their ancestors.
Q3: I don’t understand why Z would need to be more distant… In fact, Z could even be a closer cousin – you need to determine that through the genealogy. Z could be a cousin almost anywhere out to or beyond 0068 or 0069.
Hope this help, Jim
LikeLike
Thank you, JIm. This is very helpful.
LikeLike
Pingback: The Life of a DNA Segment | segment-ology
Pingback: segment-ology
Pingback: Om DNA-matches – hvor langt tilbage kan du komme? | Hvor stammer jeg fra?
Thanks for your discussion about recombination and the anticipated number of segments going back each generation. I was curious about what percentage of DNA would fall below the threshold for IBD detection when you got multiple generations back. Using a random number generator to simulate recombination sites at each generation (34 recombinations per generation) I got that at 10 generations back approximately 15.9% of your DNA would be segmented below the 7 cM threshold (12.3% below 6 cM, 9.9% below 5 cM, and 6.4% below 4 cM). Because these segments are below the limit of detection for each testing site, one would never be able to identify matches for that portion of the genome. I did the same analysis for generations 2 – 9. Obviously, the further you go back, a greater percentage of DNA is below the limit of detection. (For example at generation 2, Great Grandparent level, only 1.5% of the DNA was below the 7 cM threshold). Anyway, if you are interested in seeing more of my data or my methodology, I would be happy to share.
LikeLike
Aaron, Thanks for your comments. I’ve been Triangulating for the past 7 years, using shared segments, over 7cM, from three companies and GEDmatch. I’ve mapped Triangulated Groups that are mostly heal-and-toe across each chromosome, covering about 98% of my DNA. I’m pretty sure that last 2% is probably made up of small TG segments, and is in line with your simulations. So as I walk the Ancestors back on each Chromosome, I can expect small, additional voids to appear at each generation going back. Once I have a chromosome map for a generation, I could then lower the threshold to say, 6cM, and look for Match/segments to fill those voids. Yes – if you already have something written, I’d be glad to read it. Jim
LikeLike
Pingback: The Fundamental Building Blocks of Genetic Genealogy | segment-ology
Gary, Thanks for your kind words. Glad to be able to help, Jim
LikeLike
Thank you sir. This is not only technically helpful but it’s also great to hear an “on the right path” comment after every few years of floundering. 🙂
Thanks for your input and for sharing your work here.
Gary Hamilton
LikeLike
Gary, The point of #8 is the word “exactly”. Rarely do you and a Match get “exactly” the same segment. What usually happens is that you get a segment from an Ancestor, and your Match gets a segment from the same Ancestor which overlaps your segment – what you “see” in a Chromosome Browser, or table of shared segments, is only the part that overlaps.
Please refer to the Version 3.0 Chart at https://isogg.org/wiki/Autosomal_DNA_statistics for the possibilities of 120-140cM Matching – probably between a 1st cousin twice removed and a 3rd cousin once removed and several possibilities in between.
You are on the right path. The values you have are just right for the ancestor of interest.
I’ve tested at AncestryDNA and with a similar situation, I downloaded the ancestors of all the Matches in the Triangulated Group, put them in one spreadsheet and sorted on the ancestor names – a clear “winner” was evident. If not, then collect more Matches with Trees.
Good luck – Jim
LikeLike
Hello Mr. Bartlett,
This question is in reference to your Summary point #8 in this post: “The odds are very small that you and a Match would get exactly the same segment from a CA. And certainly the odds would be extremely small that you and several Matches would get exactly the same ancestral segment from a Common Ancestor.”
I’ve been doing a lot of reading the last couple of weeks after finding what I think is a triangulated segment inherited from my paternal GGF who was adopted at a very young age and could not identify his birth parents or birth surname. He is the primary focus of my research.
I have a group of 11 individuals who match me, my sister, a first cousin and a 2nd cousin and my dad (via GEDmatch phasing) from 121 or 126M to about 139 or 141M on chr4. This group and I cannot identify any MRCA or even common surname (yDNA tells me my GGF was actually a Gilliland by birth).
My question is based on your point #8 is the range of 121 or 126-139 or 141 cM illogical, i.e., extremely small that this would come from a 3C or more or do I misunderstand your statement?
Thanks for your input.
Gary Hamilton
LikeLike
Jim, forgive me for hijacking your blog, but I know you respect other people’s opinions, as well.
In answer to “what would papa do”, I am only a Genetic Genealogy Hobbyist, not a Scientist, and I only have MHO. And, we 74-year old women do have opinions.
I agree that most 15th gen matches are only population pool matches, and not real. Many Scientists opine that that is 0% likely that we would share dna after 5-6th cousin. But then there are sticky segments that persist over time…….Variables in Dna.
Dna can disprove the paper. A woman I know had the name of the man her mother was married to when she was born on her birth certificate. They had only been married 7 months. With segment matching and trees it was easily proven with her numerous real cousins who had tested that the name on her birth certificate was not her bio father.. But, the paper did not have to be disproven, because the mother of the child had already ‘fessed up’ as to the real father.
I start with a tree match, and then attempt segment matching. The further back, the more difficult because in MHO many trees are wrong, or NPEs abound. My starting point is a common ancestor in our trees. Only then, will I pursue TG, segment matching
DNA is scientific, but for some of us, it is also based on belief.
JMHO
LikeLike
Caith, I do value all input – I’ve never deleted a comment to this blog. You can see my reply below. Jim
LikeLike
I just realized you were talking to and about the other Jim (Bartletts) not the Jim of WhatWouldPapaDo. So help this Jim, a 68 year old man, understand what is MHO and NPE mean?
I am attempting to discover the value(s) of genetic DNA analysis. As a four and half decade researcher I have discovered most of the advantages and disadvantages of paper research. One of the early discoveries was that when people falsify or cover up an occurence it is because they do not want others to know. It is not something new as I have uncovered the same type of event that Caith mentioned occurring four and five hundred years ago. People are often hurt, angry, and bitter when events, meant to be unknown, are published to the world. In Caith’s example all the numerous cousins, the child, the mother, the real father, the non-biological father, the real father’s family, future generations, and on and on are all affected by this reveal. So DNA is a two-edged sword that can both heal and hurt. And in my opinion not something to be used lightly. But I can really acknowledge that DNA analysis can uncover these types of occurences.
I think most of us would agree that DNA analysis loses its individual predictive ability at 5-7 generations, but so do most paper trails. If we can agree upon that then DNA has a predictive ability of under, say, the sixth generational level. Which is about the same level where modern paper records are available. But what comes first the paper or the DNA? In all those cousins that I have discovered through DNA (primarily Ancestry) the confirmation was made through a paper trail. In just as many instances where there was a DNA match but the paper trail never aligned. But in the vast majority of cases, one party or the other to the DNA match does not have a paper trail to confirm a match. Many times I have found that the other party want me to provide the paper trail and become disappointed or even angry that I can’t. So in the above scenerio what is important is the paper trail and DNA is used to potentially confirm it.
I can see one other use for DNA in genealogical research. I have worked with a man who has a common surname and can take his ancestor (X) back to being born in 1804 in Kentucky. This man has done more paper trail research than any of us would believe to be available. Still there is no paper trail that tells him who the ancestors of (X) are. But he has enough paper trails to suggest at least three individuals (A, B, C) as being the father of (X). So what he is attempting to do is locate proven descendants of A, B, and C; and to do genealogical testing with those proven descendants. In that way he can focus his paper trail on the correct branch of his surname.
So in my opinion DNA is useful at the 6th generational level and under to:
1) Uncover falsehoods in a paper trails.
2) Find connections in paper trails.
3) Focus paper trail research.
I have to wonder if it is worth the time and money to uncover those falsehoods that might hurt the living or to find those 5th, and 6th cousins who we don’t know from Adam and could care less about. But it I might find it worth the time and money to focus a paper trail reseach line. After all, I spend a lot of money on paper trail research.
I am an educated man and if I take the time and effort can learn all about segments, genes, etc. But what I really want to know is how much faith to put into various levels of DNA matches. What does cousins at the 5th level statistically mean? If nothing, then what do I need to understand to make a 5th level match meaningful. In other words tell me what i need to learn.
Sincerely,
Jim
LikeLike
I will reply to your questions to me, then I should exit, because this is Jim Bartletts blog and he is the professional.
MHO means: my humble opinion. JMHO means: just my humble opinion. NPE means: non-parental event, which is a euphemism for Illegitimate.
I have also disproven/proven a line with mtDna testing, mitochonial dna, which is the maternal line upstream, back in time; and downstream, forward in time of a female.
There was a myth in my family that my great grandmother was NA (Native American). Well, I could prove that was untrue because I have had full sequence mtDna testing, and I am U3a1b; and that is NOT an NA haplogroup.
I have since discovered where the myth originated. My great grandmother was wife #1, and not NA, but my her husband (my great grandfather) did marry a NA lady as wife #2. I have communicated with a descendant of wife #2 who confirms this with paper.
LikeLike
Jim,
You can always just use traditional paper-trail research – standard genealogy techniques. You can build a case for descent with records. The issues is that you cannot, without a LOT of other evidence, say the relationship was proved by DNA.
Good luck,
Jim
LikeLike
After over four decades of using the classic tools of genealogy to discover my history, I decided to give DNA a try. What I have since discovered is that I have to use those classic tools to prove what DNA might suggest is a relationship. Twice DNA suggested a relationship that I decided to follow due to the closeness of the suggested relationship. Both times it was a “scandalous” hidden relationship and both times it took paperwork to come up with the connection. I have posted by DNA on three sites. One site gives me decent suggestions, the second gives suggestions that I have no idea of where they came from, and the third has provided a single suggestion. While I can see a few narrow uses for DNA; on the large I see it as a waste of money. But then again, I never bought liederhosen to have to trade in for bagpipes. Thanks for your remarks, insights, and patience. I think I will stay with the paper trails.
Jim
LikeLike
DNA Never Lies!!
People sometimes lie, Paper/records sometimes lie, but DNa never lies!
We just have to know how to interpret DNA.
And that is why we do TG segment matching: To “prove the paper.”
LikeLike
Oh, I quite agree that “prove the paper” is an appropriate use of DNA in genealogy. However DNA does not necessarilly disprove the paper. But at the level of 15th generational matching, the original question, it is quite worthless. So here is a question for you, at what generational level does the use of DNA become questionable? Let’s assume that you and I have no paper trail to refer to. We have a DNA match that says we are sixth cousins. So are we really directly related or is it random? So while DNA may not lie, it really is just statistical probability.
LikeLike
Jim, Let’s try to reconcile some hard evidence. I just passed 50,000 Matches at AncestryDNA (who uses population phasing to greatly increase the odds that the shared DNA is true). I have about 2,000 4th cousins (4C), which is the 5th generation back. So what about the other 48,000 Matches? Most of them are based on valid IBD shared segments; and I think we can generally agree they aren’t all 5C. Actually there is some distribution curve of all of our Matches. Let’s say 4% are 4C and closer; how would you guess the distribution is for the rest. Clearly many of them are 5C and 6C and 7C, etc. Based on my (considerable) experience, I think the bulk of them are 6-8C and then the curve drops off for the next 10 generations. The distribution curve (of cM vs cousinship) would be the same at every company. Another reference is Figure 2 at this ISOGG/Wiki page: https://isogg.org/wiki/Identical_by_descent This also shows a very distant probability distribution of IBD segments out to 20 generations. They exist! And many of our Matches have those segments from distant ancestors, and some have those segments from closer ancestors.
As we gain experience in using the current atDNA data and tools, and begin stretching our genealogies, we will gradually push out the number of generations we can work with. The limiting factor is not the DNA test, it’s our known ancestors in our genealogies. Jim
LikeLike
Can DNA help us prove anything at the 14th generational level? I recently discovered a potential cousin. His family line starts in the early 1500s as does mine. We both agree that at my 13th generational level that we are not related. My line goes back several more generational levels. We both agree that at my 14th generational level there is other evidence that we could be related at that level or at worst the 15th generational level. Can DNA prove anything at that level. Would we be wasting our time and money?
LikeLike
whatwouldpapado, We cannot “prove” any relationship with DNA alone – there are just too many variables and too much randomness. Although IBD segments do go back that far, how would we select one set of Common Ancestors over another? How do we know that there is in fact no NPE anywhere in an ancestral line? How do we know that the shared DNA segment is not from a closer Common Ancestor behind a brick wall, or a more distant Common Ancestor. If we acknowledge that a shared segment could come from the 14th generational level (which I just did), how can we say it could not also come from a different Ancestor at the 15th generational level? One way that is generally accepted is to “walk the ancestor back” – that means: on that same segment find close cousin whose MRCA with you is in a direct line back to the Common Ancestor at the 14th generational level; and a 5th cousin (5C); and a 6C and an 8C and a 9C, etc. back to your target ancestor. With everyone agreeing on the same line, you have a strong body of evidence. And if you were going to try to find some candidate cousins to test at that level… you are definitely wasting your money. At the 8th generational level only about 2% of your cousins would match you (you would buy 50 kits to get one Match), and the odds drop significantly after that… Jim
LikeLike
Gee I hate logic, why did you have to resort to that? We were hoping against hope for a silver bullet. Your comment of “Walking Back the Ancestor” was a new thought to me. I will keep that in mind. But for 15th century ancestors we have a lot of information on both sets of ancestors; and that information is generally impossible to come by. Our ancestors were both contemporaries off and worked with Martin Luther. So we will look into Lutheran Church archives to see if we can make a connection. We have 14th and 13th century town records that give ancestral information but nothing that connects our two branches. We also have 15th century vanitiy family histories that go back to 600BC, but really where do you stop. Interesting in that wealthy people would have priests seach to archives in Rome to do their family genealogies. I do appreciate your help.
Jim
LikeLike
Pingback: Using AncestryDNA Notes | segment-ology
Pingback: Using a Child to Determine the Side | segment-ology
Also crossovers are about 1.6 x 45 per generation on average or 72 as both paternal and maternal meiosis undergoes crossover. The Brynne example, which is just about right on the average, represents 118 segments of her grandparents’ DNA and 174 segments of her great grandparents’ DNA. Of course the 3400 cM are per the 23 chromosomes or 6800 per the 23 chromosome pairs. Ignoring the x chromosome pair for Brynne, 50 segments were spread across the paternal 3400 cM and 65 segments were spread across the maternal 3400 cM. The segment length is a function of an ancestor’s position as the male line will have the largest average segment length and the female line the smallest for any given generation.
LikeLike
Correction 73 recombinations 45 maternal 1 on 8 and 2 on 3
LikeLike
Also 119 segments including paternal X.
LikeLike
Interesting but Brynne’s data (see Kitty Cooper blog) on what she inherited from her great grandparents is real data. Her data chromosomes showed 174 segments, representing 128 recombinations, are inherited from her great grandparents (20-20-18-24-23-24-24-21). Some of the recombinations between her grandparents and her parents have disappeared from recombinations between her parents and herself. She is the result of 72 recombinations from her parents of what her grandparents passed on to her parents, 28 paternal (0 on 4, 1 on 11, 2 on 5, 3 on 1 and 4 on 1) and 44 maternal (0 on 2, 1 on 9, 2 on 2, 3 on 9, and 4 on 1). It would be interesting to see the distribution of recombinations for each of the 46 chromosomes we inherit (female meiosis to male meiosis recombination frequency is 1.6:1).
LikeLike
Bill,
In my post I noted the difference between males (about 27 crossovers) and females (41 crossovers) – different references have slightly different values, which are based on observations. And when a male applies about 27 crossovers, he is subdividing both his paternal chromosome (with 27 crossovers from his father) and his maternal chromosome (with 41 crossovers from his mother) and each child gets half – so the difference male/female ratio quickly goes away. So combining both parents’ inputs, our new set of 46 chromosomes would have a total of about 68 crossovers, resulting in about 114 segments from the 4 grandparents. But the two sets of chromosomes we get (one set from each parent) are totally independent of each other – so I prefer to look each side separately.
We are not at all tied to these numbers – they are the result of random DNA. Each person will have a different experience. The point of this blog post is to (1) show a general range of what to expect, understanding there is the possibility of wide variation, and (2) we can go back many generations and still have segments from Ancestors over 7cM. Lots of them, and from pretty distant ancestors – we should be aware of this, and understand that our Common Ancestors may well be beyond our genealogical horizons. These two points should be the main takeaways, not the precise numbers of crossovers. Jim
LikeLike
I recommended your blog in my blog and posted some pictures of the segment’s passed down among three generations with close family tested.
http://jenniferhsrn.blogspot.com/2016/07/segmentology.html
LikeLike
Pingback: Anatomy of a TG | segment-ology
Jim, Thanks for the great article, figure 3 is especially useful. My best match, outside of immediate family, shares about 112cM with me but we do not know the CA. (His mother was adopted.) After reading this article and looking over Figure 3, I am wondering if our connection is closer than we had guessed (3C). We share two large segments: ch1 – 53.2cM and ch8 – 35.9cM. He shares no DNA with my tested mother, so the CA is on my paternal side. I have a tested paternal 3C that is a good match to me but does not match my best match at all, perhaps that only rules out that lineage? Based on the figure, could the CA be as close as a grandparent? certainly a great grandparent? But, he only shares 22cM with my tested sister, segments about 15 and 7cM on ch2 and 16, respectively… My father and his sibs are deceased, I have one paternal 1C that could be tested. What do you think? Many thanks, Barb L.
LikeLike
Barb – you are really getting into atDNA. You are correct that the Common Ancestor is probably on your fathers side. Something like a 3C only helps when they Match. A non-match with a 3C means you don’t match where the 3C matches. Usually with siblings, you’ll want to use the average share between the siblings (yourself and your sister) to estimate the range of probable ancestors..
LikeLike
Jim, What you’re not considering here is that at every generation there is a 50/50 chance that any segment will be passed on to the next generation at all. This has a cumulative effect so you would need to take into account the number of transmission events involved back to the common ancestor from say a fifth cousin, a 6th cousin once removed and a 7th cousin. It’s the equivalent of tossing a coin many times in succession. If a single segment survives 20 transmission events in three cousins it’s the equivalent of tossing a coin 20 times in a row and getting heads each time. If you toss a coin millions of times then of course this will happen but it will be a rare occurrence. The other complicating factor is that in this 50/50 lottery a whole chromosome can be wiped out. If you look at the comparison I did with my son and his maternal grandparents you’ll see that in one transmission event he lost his entire chromosome 22 from his mum and his entire chromosome 18 from his dad: http://cruwys.blogspot.co.uk/2016/02/a-second-study-tracking-dna-segments.html. Once that chromosome has been lost it can’t suddenly reappear again in a future generation. I’ve only seen a few comparisons between a grandparent and child but I think in all the examples I’ve seen at least one entire chromosome has been wiped out. It would be interesting to know how often this happens. What your diagram shows is one roll of the evolutionary dice in one individual but two people who share the same 7th cousin aren’t going to have their chromosome chopped up in the same way. They will receive a different combination of segments from their ancestor and not the same ones. And you still have to take into account the chances of a segment surviving the 50/50 lottery each generation at each generation. The chances of two 7th cousins sharing DNA through descent from one specific ancestor are remote at best, and that’s if they share any DNA at all. However, you and your seventh cousin will be related to each other in many different ways. You might be eighth cousins, 10th cousins once removed, 6th cousins twice removed, 15th cousins, 20th cousins, etc. You therefore have a lot of possible relationships from which you could share your DNA. That’s why people are seeing these triangulated groups and not because they are receiving the segment from the single ancestral couple that they all happen to have identified in their family trees.
LikeLike
I meant to say in the above that my son lost his entire chromosome 22 from his maternal grandmother (my mum) and his entire chromosome 18 from his paternal grandfather (my dad).
LikeLike
And your son got an entire chromosome from his paternal grandfather… There are always two sides to that coin, such that your son got a full genome from each parent.
LikeLike
Debbie, I don’t think you are comprehending my blog posts very well. You are focused only on the worst case scenarios – I am focused on what is really happening. Figure 1 shows an example of the segments you do get from a grandparent, inlcuding Chr 21 which you do get, intact, from a grandparent (yes, you don’t get that chromosome from the other grandparent – if your cup is always half empty – but you do get every part of your genome from one grandparent or the other). The same is true in Figure 2 – all of these segments – each from one of the 4 great grandparents on one side – have already passed the 50/50 test. After all of the 50/50 coin tosses, you must get DNA from same ancestors of each generation that fill up every chromosome. This blog focuses on what you do get, not what you don’t get. Likewise Figure 3 shows what you tend to get at each generation (after all of the coin tosses). If you’d read all of my blog posts, including this one, you’d see where I acknowledge the lost DNA – never to be seen again. It happens all the time. I don’t care about what we don’t have – in genetic genealogy we need to look at what we did get – and it fills up every chromosome. We have lots to work with. And Figure 3 highlights the fact that at the 7C level we will average 13cM ancestral segments from those Common Ancestors. Not all of the 128 6G grandparents will pass down these segments to us, but enough of them will to fill about 295 different ancestral segments in my chromosomes. focus on what we did get. Please study these Figures until you comprehend what I’m trying to describe. These are not templates for my genome, or anyone’s – they are representative examples, to give the reader an idea of roughly how ancestral segments are formed, and roughly what sizes to expect. And I’ve invited readers, including you, to try dividing up 23 chromosomes with an average of 34 crossover points per generation, for 8 generations and see if you come out with about 295 ancestral segments spread over the whole genome. This is very simple math. Some will be larger than 13cM, some smaller. Yes, the “chances of two 7th cousins sharing DNA through descent from one specific ancestor are remote…”, but it happens all of the time. At AncestryDNA, with “phased data” that Ancestry says is 99% correct, I have over 10,100 Matches – or over 10,000 IBD Matches – beyond any 4C. Surely you don’t think they are all 5C, or that they are all 25C – they are spread in a distribution curve. Since I have 400 4C, let’s say 1,000 are 5C, and 3,000 are 6C and 3,000 are 7C and 1,000 are 8C and 2,000 more are spread over more distant cousins. The point is I have lots of Matches who share IBD segments at AncestryDNA (I have many more from 23andMe, FTDNA, and GEDmatch). At the 7C level they have to overlap my roughly 261 ancestral segments from my 6G grandparents (probably not all of them, but some of them). Since they each have an IBD segment, they have to overlap (i.e. match) that part of my DNA where the overlap occurs – on my maternal or paternal side. You can flip coins until the cows come home, but IBD shared segments match my DNA where they occur! Because it is and IBD match, it came from an ancestor who passed down that segment to both of us. This only occurs at roughly 261 places on one genome (from 6G grandparents), and each of those places is fixed by start/end locations created by crossovers. I don’t care how the math is interpreted, I believe what I am seeing in my Match lists – their shared IBD segments overlap each other all over my genome, and and I don’t think it’s by chance that they fall between crossover points. Please try to envision how this does work instead of using math and statements by AncestryDNA (which you and I both admit we don’t fully understand) to try to explain that it cannot happen. It is happening! So we need to look at how and why it is happening. As I’ve said before, we don’t need genealogy to form TGs. Forming TGs is purely a mechanical process. We have many shared IBD segments – each one has a start and end location. When they overlap and match, they have to match our ancestral segment on one side or the other. There is no other choice for an IBD shared segment. Linking Ancestors to these TGs is a different, genealogy focused, issue. We first have to understand that ancestral segments are real – and the TGs that form around them are real, and that there can be many IBD segments in them. Determining which Ancestor provided the ancestral segment is another process.
LikeLike
Jim, I am understanding your blog posts and I understand how recombination works. We don’t need to do the mathematical calculations there’s a very nice four-generation chromosome map here compiled by Angie Bush showing a real-life example of how the segments get chopped over the generations:
http://blog.kittycooper.com/2014/09/using-the-chromosome-mapper-to-make-a-four-generation-inheritance-picture/
We know that this phenomenon of triangulated groups is being observed but we still don’t know how many of these TGs are just an artefact as a result of lack of phasing. We therefore have no way of determining whether or not they are real. We really need AncestryDNA to give us access to the raw segment data.
Phasing rules out all the false positive matches as a result of the alleles criss-crossing between the maternal and paternal chromosomes but that is only the start of the process. Even if all these TGs are real and not the result of a lack of phasing there is still great potential for error because we’re only using 700,000 SNPs and not the whole genome. Just think of how many matches you lose with an mtDNA test when you go from HVR1 to a full sequence.
You also seem to be assuming that every single one of your matches will share a common ancestor in a genealogical timeframe. However, If you pick any segment on your genome and compare it to the entire population you will find that many of those segments will match thousands of people in the population simply because you are all human, you all share European ancestry or you all share ancestry from Virginia or Maryland (this is the literal meaning of IBS). Yes you will have received such a segment from one of your great-grandparents but if that segment is also shared by most people with ancestry from Virginia then you can’t assign it to a specific ancestor seven or eight generations ago because you have no way of telling by which route it reached you. It could have a TMRCA going back 1000 years or more. We don’t know what the distribution curve is for our matches but my guess is that the vast majority of these matches are far more distant than you expect.
At the moment we seem to be going round in circles debating these issues. I suggest we wait until we get some good data on whether or not these TGs withstand phasing.
LikeLike
“…some 7G grandparents contribute to several ancestral segments. Your ancestral segments are in the 11-12cM range, on average.”
Of course there will be a bell curve and outliers will produce seemingly improbable results, particularly with prolific families. I doubt that segments from 7G grandparents that are 20 cM or larger are hard to find. Identifying the ancestry is not easy, but I think moderately large distant ancestor segments are probably ubiquitous.
LikeLike
Keep in mind the difference between ancestral segments (shown in the figures) and the shared segments which tend to be somewhat smaller. But the IBD shared segments are on a very broad bell curve, and we do see them overlapping the ancestral segments.
Jim – http://www.segmentology.org
>
LikeLiked by 1 person
Thank you for this post. The chart is invaluable. For the first time I can see why segments are the size they are.
I have been reading, although not necessarily completely understanding, the discussion of triangulation in the Facebook ISOGG forum. People are concerned about the ability to prove that if we find we have a segment from 6th great grandma shared with 3 people, it came from one common relative, rather one or more of the segments coming from a more distant relative, but by a different route.
I googled 3 Birthday Paradox, and someone on a site called math.stackexchange had calculated the probability of having three people with a birthday on the same date at .03 for a group of 23 people, but .79 for a group of 100 people. Coincidentally, per your table, this is just about the calculation we need to predict whether some three descendants of an ancestor the 10th generation back will inherit the same segment from the ancestor.
I have triangulated groups where at least three people share overlapping segments 13 cM or more (the average size of a segment I would get from a 6th great grandma). With a 6th great grandma, we are dealing with a 3 Birthday Paradox with a year of only 261 days, so, to me, the probability is even greater that some of 6th great grandma’s grandkids will share with two of their cousins the same segment they received from her.
And the probability seems high if I have these three segments, they came from 6th great grandma, not some more distant relative. I don’t care if the more distant relative is a possible source, as long as I am not going astray thinking 6th great grandma is the probable source.
I realize that, as you point out, most of our TG’s are spread out, often with a 3rd or 4th cousin spanning more than one. We don’t inherit a segment from a single ancestor but are part of a stream going back to the origin of the species. So if I share at the same location 17 cm with one ancestor, 13 cM with another, and 9 cM with a third, and if I can trace a paper trail from 17 to 13 to 9, then it seems also there must be a high probability the 9cM segment has passed along the same stream, even if I know of alternate streams to get to the 9 cM ancestor.
I think you have solved the issue for me, but, as I have been obsessing about this for the last few days, I would very much appreciate if you would point out any errors in my ideas.
LikeLike
Dave, Actually I think you have a very good insight on this. It is fairly complex because the segments for each generation are stacked on top of each other. When we form TGs, they are not all at the same generational level. This is coupled with the fact that many segments are “sticky” – that is they are the same size on several generational levels. In other words a specific 10cM segment may be identical in a 5G grandparent, a 4G grandparent and a 3G grandparent – no crossovers in that area of your DNA for 3 generations. So when you triangulate, it may involve a 6C, a 5C and a 4C. And you might also match a 3C on this segment and his/her shared segment is larger than the TG. And you might also match an 8C on just part of this TG, indicating that the TG might split into two TGs if you get some more distant Matches. All we can do at this point is use our genealogy skills and determine Common Ancestors with the Matches in each TG. If we can do this with several Matches who have CAs with us that are all in the same ancestral line, this is very promising. Because all of us probably have some endogamy in our ancestry, there are usually several different ways we can be related to each Match. But when widely separated cousins start to all come to the same ancestral line, the odds go up a lot that we’ve found the genetic connection. I’ve seen the Birthday probability before – it’s a good “bar bet” that you’ll usually win. I think we have so many true genetic cousins in our Matches these days, and only two options for them to match our DNA (the maternal side or the paternal side), that there has to be a growing number of Matches on each TG. I think the math arguments are very misleading – particularly when we see the evidence in our Match lists of so many IBD shared segments – they have to go somewhere (no matter what the math says). So I think you are thinking this out correctly – it is not as simple as just a flat jigsaw puzzle – there are many levels to it.
LikeLike
Where do I find these segments you talk about? Most of my testing has been done with FTDNA. I have Y testing from 12 Marker to Big Y, MtDNA Full Sequence, 23andMe, and Family Finder.All these tests have not proven anything so far. I would like to have something to help talk others into taking more tests.
LikeLike
Donald
These segments are all autosomal – Family Finder only – no Y, no mt. Go to your chromosome browser and at the top right click to download all your segments. I strongly recommend you sort this list on the centiMorgan column and delete all rows less than 7.7cM. That will leave you with at least one segment for each Match. Then sort on chromosome and start to line the segments up. Then re-read the blog posts on Triangulation. I don’t want to repeat all of that here.
Jim – http://www.segmentology.org
>
LikeLike
Hi Jim, In the Figure 3 table, you show the average shared cM with a 1st Cousin as 425. But shouldn’t this be 850? Since we’re only looking at one genome, a first cousin will share about 25% of that (if the cousin is on that side of my family) or none of it (if the cousin is on the other side). Am I right?
I very much enjoy your blog, and I’m doing my best to identify my own TG’s. Thanks for taking the time to share your insight and reasoning.
LikeLike
John, I think my numbers are correct. The ISOGG table at http://isogg.org/wiki/Identical_by_descent are for both parents – and show 850cM for 1C. But my Figure 3 is just for one parent (one genome of 23 chromosomes), so the shared cM would be half.
Thanks for your words of encouragement. Forming TGs is a tedious, mechanical process – no genealogy needed until you need to assign the TG to the maternal or paternal side. But once you determine the TGs, new Match segments tend to easily fall into place. In the long run, it’s well worth the effort – IMO.
LikeLike
Hello Again Jim,
I agree that your numbers are correct for the average amount of DNA shared in total with a given cousin. But the point I was trying to make is that when we’re looking only at one genome (either what I got from my Mother or what I got from my Father), a particular first cousin will share either about 25% of that genome with me, if the cousin is on that side of my family, or will share none of my DNA on that genome. So the average is about 12.5% shared in total, but compared with one of my genomes, it’s either about 25% or zero.
It makes a difference, because in the “Discussion of Figure 3”, Gen 2, you say that a person normally shares 106 cM (from one side) with a 2C, and therefore since the average segment size from a great grandparent is 37 cM, you might expect to share 3 segments (3*37=111, which is close to 106). But in fact, if the 2C is on the “correct” side of my family, I should share 212 cM or about 6 segments on the specific genome we’re looking at, (and zero cM on my other genome).
Your description sort of makes it sound like I’d expect to share 3 segments totaling 106 cM on each of my two genomes with a particular second cousin. But that’s not true. The cousin is closely related to one of my parents, but not related at all to the other.
LikeLike
Thanks Jim. This is what I’ve observed in my own results. When I have enough shared segments in a spot I can tell where my ancestral segment ends. I can look at two of the others in the group and some of them continue on sharing, so I know it’s my segment that ends (same with the beginning point). Your triangulation methods have been what have enabled me to find the triangulated groups and in some the shared ancestral line.
LikeLike
Nan, thanks for your comments, and particularly for the fact that you’ve done the work, and have experience with TGs. As you take advantage of all the shared segments you can find, the crossovers will start to firm up all over your chromosomes. The hard spots are segments from recent immigrants or ancestors who had few children/descendants.
Thanks again for your feedback.
LikeLike
Jim, I have stumbled upon a method that is helping me to find crossovers. I have a paternal Irish immigrant (a 2Ggrandfather) in my main paternal line, whose place and DOB is unknown, but estimated. I have extensively documented, as best that I can, his known children and descendants. I have a growing group of those who are testing (mostly with Ancestry) and who have agreed to upload their DNA results to Gedmatch. I have Excel spreadsheets with all of the data available from all of those who have uploaded, but am finding it useful to compare the Gedmatch one-to-one results with each of my confirmed 2nd or 3rd cousins with each other, in addition to myself. When they match each other (usually higher amounts of cMs than they do to me – if we match at all) I enter that information in a colored cell sheet row. I make a notation that these cousins share at that location, but not with me. I seem to have been “admixtured” out of some of the DNA that would be helpful, but think that this information should still be helpful. The results for those who match me (where my cousins match and I don’t) are from my maternal line, rather than paternal. Am I on the right track, although perhaps going about it the long or wrong
way?
LikeLike
Cheryl,
You are absolutely on the right track! There are two things to keep straight here: the DNA your ancestor passed down to descendants; and the DNA your ancestor passed down to you. When you triangulate your own shared segments, you get a good estimate of the crossover points in your DNA. When you triangulate all of the shared segments among your Matches you get an estimate of what your ancestor’s DNA looked like. Remember – Triangulated segments are the equivalent of phased data – you just don’t know the specific ACGTs, just that they are the same for each overlapping segment in a TG. You can determine TGs for each of your Matches by using them, one by one, as the base. You then have their crossover points – which are usually all different from each other. I have a column in my spreadsheet for the base person – usually me. But whenever the shared segment also matches my father, I just copy my row and change the data (usually very slightly) for him (and put his initials in the base person column). Periodically I sort the spreadsheet on the base person and move my father’s shared segments to his spreadsheet. Sometimes I’ll add in a spreadsheet for my brother, son, or uncle to make sure I’ve accounted for all of the overlaps (and any MRCAs I’ve found), and then separate the spreadsheets again. (be sure to make backups first and often…) Jim
LikeLike
Jim, I know what phasing is, but what do you mean by, “AncestryDNA’s phasing program”? I have tested at Ancestry and I have never seen in writing anything about their phasing program. What am I looking for, and where am I looking to see how phasing at Ancestry is pertinent to me and how I interact with it.
Maybe I just did not get the memo. LOL
LikeLike
Caith, We didn’t get a "memo" about it, but there are several places at your AncestryDNA pages where they have a little “i” in a circle – click on these for more information – they have White Papers that describe a lot of their processes.
LikeLike