
A summary of some different Clustering programs is here. I’ve used, and liked, most of these programs, and I want to highlight one of them here.
Shared Clustering by Jonathan Brecher is a good, flexible tool – it does what I want, quickly. It doesn’t have the glitz of Genetic Affairs or other features offered by DNAGedcom Client. But it gets the job done for me, efficiently, and it’s free. Some detailed steps at the bottom of this post.
Some comments on Shared Clustering:
– I used a 6cM threshold and downloaded all my 118,853 Matches (and Shared Matches) at AncestryDNA in 2 hr 34min.
– I then ran a Cluster report with a 90cM threshold in 2 seconds (that’s not a typo): 34 Matches in 8 Clusters.
– Each Cluster is assigned a number.
– Each Match is shown in one Cluster – the one with the most matches to other Shared Matches – the most “heat” in a heat-map program.
– AND all of the Correlated Cluster numbers are also shown for each Match. These are Clusters where the Match also has an affinity – the Match shares some Shared Matches with the rest; just not as much as in the Cluster it’s assigned to. This is very handy, because sometimes our known relationship with the Match would be a better “fit” in one of the other Clusters – feel free to use judgment and assign a Match to any Correlated Cluster you want. OR, if a Match shares two segments with you, assign it to two Clusters. Omygosh – that violates the Cluster “rules”! But this is your data now, use your own judgment and bend the rules a little – just don’t get too wild…
– I ran multiple other Cluster reports, each one took only a very few seconds.
– With a threshold of 28cM, I get 1105 Matches in 94 Clusters – in 4 sec. For me, that’s about one Cluster for each of my 5xG grandparents. Of course, it won’t fall out exactly this way, but that’s the general area of my Tree I’d be working in with these Clusters. Remember: Clusters tend to form on individual Ancestors.
-Each report includes a one-click link to each Match’s DNA page with me – very handy.
-All of the ThruLines Common Ancestors (CAs) are also included for each Match – a convenient check, if you haven’t already summarized each of them in the Notes. Or if you are just checking for new Matches among your ThruLines.
-Each report includes all of my Notes (into which I’ve already summarized ThruLines, other CAs and TGs).
-VERY IMPORTANT: I can modify as many of my Notes as I want in the spreadsheet, and then easily click to upload that info back to AncestryDNA (it overwrites the Notes that I’ve changed – WOW, what a time saver). This uploads in under a minute. Use this feature to summarize ThruLines CAs into your Notes (if you haven’t already), and upload that back to AncestryDNA. Use the “Upload Notes” TAB.
-ALSO IMPORTANT: I can use the “Export” TAB to download my AncestryDNA data, including Notes, to an Excel file, giving me an inventory of all my Ancestry Matches (without the Clusters or Shared Matches). This is my go-to file whenever I’m searching for an Ancestry Match (like from a name or email at GEDmatch). It’s much better than using the AncestryDNA search system. And the hyper-link means I am just one click away from my Match’s DNA page with me.
Some steps to get started:
Go to this page to download the program to your PC: https://github.com/jonathanbrecher/sharedclustering/wiki
Read the Home page, and then click on the download link on the right side (if you get a popup warning, tell your PC it’s OK)
Read the Introduction TAB, then select the Download TAB
You are now working from your own PC – enter your Ancestry username and password and select your test.
I click on “Slow and Complete”, but feel free to try each of the radio buttons. I set “Lowest centimorgans” to retrieve to 6cM and get all my 118,000 Matches in about 2.5 hours. Note where your file is stored. If you set “Lowest centimorgans” to 20cM , you’ll get all your “forth cousins” and closer in less than 10 minutes – this includes all the Matches who are used as Shared Matches.
After the Download is complete, select the Cluster TAB – the Saved Data File (from the Download) is usually shown by default, but you can also use files downloaded from other companies, if you want. The Cluster output file usually shows by default too – it’s the same name as the Saved Data File with “-clusters.xlsx” appended instead of “.txt” You can change the name of this file if you want – I usually append the default cM I’m using (e.g. 28) after “clusters” so I can save them all with different, recognizable, names. Just make sure both files (the Download “txt” file and the title of the new clusters “xlsx” file) are in the same folder. I’ve also set up a Clustering folder, and a sub-folder for the Shared Clustering program, and separate sub-sub folders with a date of the initial download file (e.g. 20191123) – so the Download and each of the Cluster runs would go in that (20191123) folder. A little work on organizing a file system really helps me remember what I’m doing….
Click on the “Cluster completeness” button of your choice; and type in the “Lowest centimorgans” box. Then hit Process Saved and wait about 2 seconds.
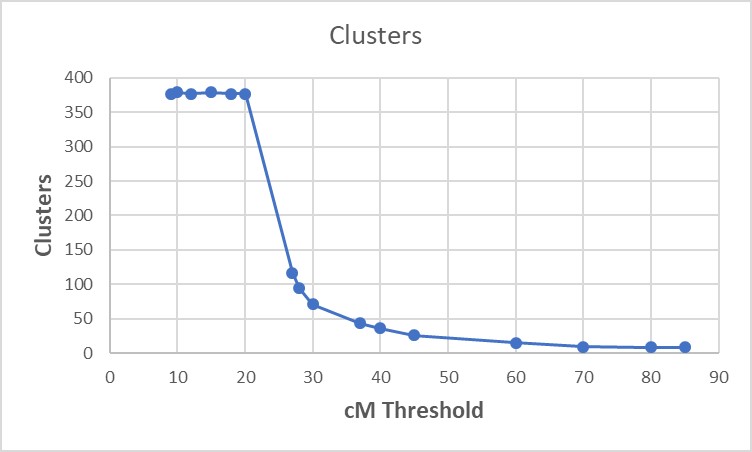
This Chart shows the relationship between the cM Threshold selected and the number of Clusters that result (for the Download of my data). Your results may vary, but the shape of the curve will be the same. The curve flattens below a 20cM threshold, because the Shared Clustering uses the Clusters at the 20cM threshold as a base and adds the other, smaller cM, Matches to the Clusters formed at 20cM. The smaller Matches (below 20cM) often have Shared Matches (all of whom are 20cM or higher), but there are no additional Shared Matches below 20cM. Experiment with your Download – it only takes a few seconds to change the Threshold cMs and get a new set of Clusters. NB:The Cluster numbers are uniquely formed during each Cluster report. They do NOT follow the Matches to other Cluster reports – they shouldn’t, because the new Clusters (formed on Ancestors) are different at different generations.
Jonathan monitors the Shared Clustering facebook page, and he’s always been very responsive. It’s good to visit that page and follow the conversations. And ask questions. And request improvement features.
https://www.facebook.com/groups/sharedclustering/
I will try to post soon on my Walk The Clusters Back project, using Clusters that should be focused on different generations in my Tree – very successful.
If I’ve messed up anything in this review of Shared Clustering, I hope Jonathan Brecher and/or other readers will provide feedback in the comments.
[19C] Segment-ology: Shared Clustering – A Great Tool! by Jim Bartlett (20191129)

Pingback: Download Your AncestryDNA Matches in 10 Minutes! | segment-ology
Yes, I’m running on Mac and have used Genetic Affairs to run this type of analysis on my husband’s matches. I ran 400-90 cM, 300-70 cM, 250-50 cM, 200-40 cM and 150-30 cM. Many of the increments available are only by 50s or 10s. The interesting thing is in the 400-90, 300-70 and 250-50 clusters I have the exact same matches in 4 clusters with 1 additional cluster in the 250-50 one. There’s GGP that is father’s father’s side, and GGP that’s mother’s father’s side, and 2GGP that is mother’s mother’s father’s side and 2GGP that is father’s mother’s father’s side. In the 250-50 cluster the additional one is 2GGP that is mother’s mother’s mother’s side. The 200-40 cluster has the exact same matches as the 250-50 one. And the 150-30 cluster has 16 clusters with many that I don’t know the connection. Many of those we’ve tried, so far unsuccessfully, to find the connection. These are due either to living people or not finding records for the MRCA. That one is interesting in that 2 of the clusters have both 2GGP and 3GGP, and 1 cluster has 2GGP and 4GGP.
I started to try for my data, but at 400-90 I have no clusters at all. At 400-50 I only have 2 clusters with 5 matches total. All of my cousins are distant, which I think is the problem. I’m an only child, only grandchild. I have only two 2C on Ancestry and one 2C1R that Ancestry counts as 2nd or 3rd cousins. I might try on 23andMe as I have a 2C there as well.
I’ve not tried to run DNAGedcom in over a year when it kept crashing on Mac. I might have to try it again sometime.
Or, as you said, maybe borrow a PC and run it, but that won’t be till after Xmas at this point.
LikeLiked by 1 person
If you can run Clustering using smaller thresholds, the Clusters start to break apart into Clusters based on more distant Ancestors. The closer cousin Matches you see now will also be in those clusters which will help you stay on the right ancestral line – all you’ll have to do is decide between the two parents… Jim
LikeLike
The ones that have 2GGP and 3GGP, the 3GGP are the parents of the 2GGP. In both cases the 2GGP is the son and his wife, so it’s father’s line that continues on both of those. There’s one that has 2GGP, 3GGP and 4GGP. The 4GGP are the grandparents of the wife in the 2GGP, and the 3GGP are the parents of the husband in the 2GGP. That’s a very interesting cluster. Genetic Affairs does auto-trees when possible, and those are showing the 3GGP and 4GGP as the common ancestors. The MRCA is the 3GGP. This is on my husband’s paternal grandmother’s side, and he has 30 DNA cousins from the 2GGP or 3GGP here.
LikeLike
Apparently this program is only for Windows. Rats!
LikeLike
Margaret, The only work around I know of is to use a PC somewhere to download the files, which you can then use on your Mac. Jim
LikeLiked by 1 person
Jim, that’s good to know. Thanks for the suggestion!
LikeLike
I haven’t had an opportunity to try this program on a Windows computer. I have a similar problem to pbcoleman529. I was trying to apply this concept on Genetic Affairs (also referring to your other posts on walking the clusters back), but feel like I am missing something basic here.
You say to “decrease the threshold” by small amounts – can you clarify what you mean by this? At Genetic Affairs, you put in a minimum and and a maximum CM value. Let’s say I want to decrease by 10 cM, if that is the smallest increment available. Would I start with, say, 90 min & 100 max cM, then the next iteration set it at 80 min & 90 max cM? Or would I start with maybe 90 min &150 max, then the next iteration set it at 80 min & 140 max?
LikeLike
Margaret, “Decreasing the cM threshold” refers to the minimum cM. In other words You’d get all your Matches above 80cM, and analyze those Clusters to determine the CA for each one (which would apply to every Match in each Cluster). Then lower the minimum threshold to 75cM or 70cM, and repeat the process. The maximum cM is used to leave out some of your closest Matches – such as siblings, parents, children, aunt/uncle or even 1C – these Matches often don’t add value. So, depending on what close Matches you have, set the maximum cM to 400cM, or so, and just leave it at that amount. I find 2C and 3C to be useful – they only cluster into one Cluster (in each run), and they insure that one Cluster stays on the right ancestral line. The maximum cM is just used to cull out any Matches who share more than that amount, so just use your judgement if you want them or not. Generally, children or siblings are not helpful. Does this help? Jim
LikeLike
Thank you, Jim, for this very good introduction to Jonathan‘s Shared Clustering tool. I‘m in the process of “walking back” two very special clusters and hope to write about them soon. Being able to link to this post will make it much easier to explain how I am doing this.
LikeLike
I got very excited reading your post. Then I checked the website, and it’s a download for Windows. No mention of Mac. I had assumed it ran on the web, which makes it work for any platform. Now I’m disappointed. It sounded like a great program.
LikeLiked by 1 person
Patsy, See my post today about Walking The Clusters Back. Perhaps you could use someone else’s PC to download the files and then use them on you Mac. I believe the Genetic Affairs Clustering program runs on the web; I’m not sure about DNAGedcom Client. Jim
LikeLike
I have been able to use Genetic Affairs with a Mac, also DNAGedcom Client in the past, although my internet connection now is too slow to make it practical.
LikeLiked by 1 person