
Here is a report on my first Match Clustering effort.
Background info:
- I used a download of my AncestryDNA Matches above 20cM (I only had a few real 3rd cousins (3C) and below, and I just left them in.
- I have made extensive use of the Notes for as many Matches as I can – all of my almost 1,000 Hints; and maybe 1/4, so far, of all my 4C and closer. NB: AncestryDNA uses 20cM as the threshold for 4C designations, but many Matches in this group are 5C and 6C and I’ve found some who are 7C and 8C, with larger than average shared segments over 20cM.
- For every Match I can, I put the Shorthand CA ID and/or Shorthand TG ID in the Note box for that Match. See the Explanation of Header row below for links that explain these IDs.
- For each Match, I also put a line in each Note which includes a summary of the CA and TG IDs found in all the Match’s Shared Matches (SM). So even a Match with a Private Tree, or No Tree, or scrawny Tree, or can’t-find-anything-in-it large Tree, will get a line summarizing their SMs. This summary often provides a very specific “pointer” to a CA and/or TG. And this added info is very helpful in analyzing Clusters.
When I ran the Cluster Matrix, I developed this summary report:

Next is a spreadsheet with the 86 Clusters, re-sorted on the CA.
Explanation of Header row:
Cluster – the Cluster # in the Cluster Spreadsheet presented to me.
First & Last – the Match # range included in this Cluster (Matches go from 1 to 3571)
SMs – the number of Shared Matches in each Cluster – a wide range…
CA – the CA ID (an Ahnentafel # – see this blogpost). When various Matches had CAs from different generations, but all on the same line, I used the most distant CA – Walking the Ancestor Back. A few Clusters had multiple CA lines, but I used CAs that Walked Back or were repeated several times.
Gen – as a convenience, I noted the generations back to the CA
TGs – the TG ID (see this blogpost). I all cases (I think) the last two numbers in each TG ID (being the TG grandparent) are in agreement with the CA ID. A number of Clusters have multiple TGs.
NB: The CAs and TGs come from my typed Notes for some Matches (I just haven’t gotten to all 3,571 of them, yet). The Notes are based on valid data – from the Match or GEDmatch (i.e. not guesses by me), but I’m fully aware that some of it is not conclusive; and another, closer and/or different, CA may be found. The TGs should not change, but often a Match will have multiple TGs, and only one would apply to the specific Cluster or CA.
Figure 1. Summary of 86 Clusters
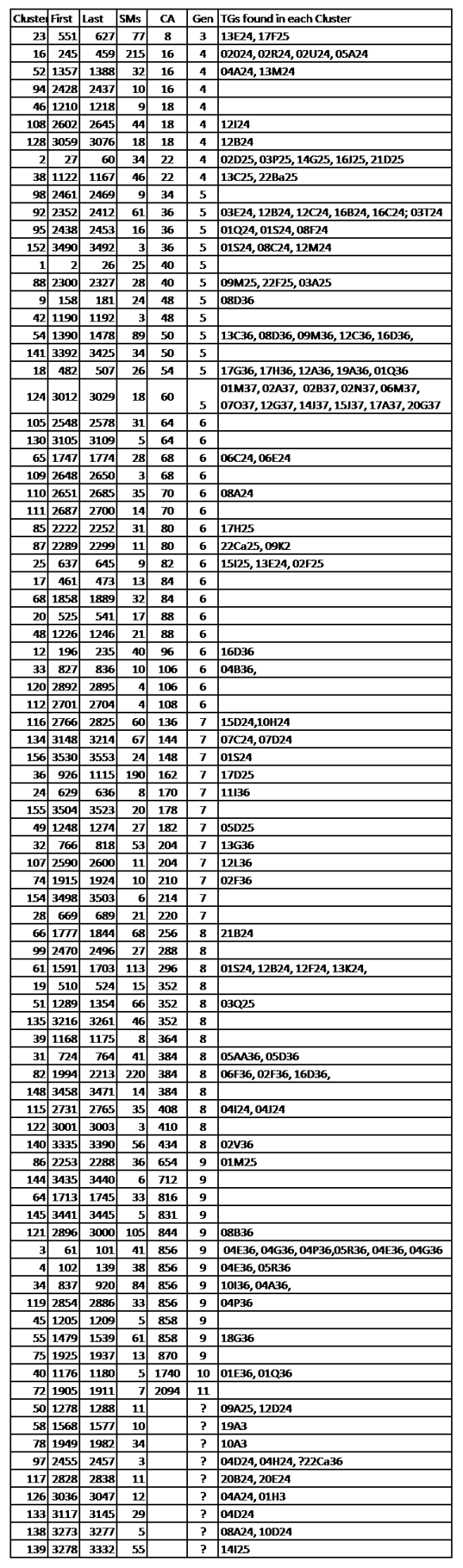
A few notes on this data:
- I am sure that, eventually, the Clusters at the top of this table will be found to link to more distant Ancestors – I just haven’t found them yet.
- I am sure that, eventually, the two Clusters in Gens 10 and 11 will wind up with different, closer CAs – I just haven’t found them yet (there are relatively few Matches in each of these Clusters)
- For the bottom 9 Clusters, I do have TGs, so I can use Matches from other companies (already included in these TGs in my Master Spreadsheet), to find likely (or at least possible) CAs. It’s just that no CAs have been determined yet at AncestryDNA for the Matches in these Clusters.
- In Gen 9, CA 856 is my prolific and well documented HIGGINBOTHAM Ancestor; and I’ve Walked this Ancestor Back in at least two TGs. There are several lines from this Ancestor who intermarried.
- In Gen 8, Cluster 61, over 100 Matches – this was a brick wall at Gen 5, until I found several dozen Matches in Gen 6-8 with CUMMINS/CUMMINGS Ancestry, which I have subsequently researched into one Tree – also a prolific line. And a new branch of my Tree!
- I’m sure there will be unfolding stories about other of these Clusters – I’m excited to see the way this is trending.
[22AC] Segment-ology: Match Cluster Report 1 – by Jim Bartlett 20190214

I may accidentally dup a reply. Have you posted your slides from the FTDNA conference on Triangulating and Clustering with Family Finder?
LikeLike
Have you posted your slides from the FTDNA conference where they might be viewed as you mentioned at your conference presentation. It would be great to see the various steps you took along the way and be able to dwell on them a bit more than the glance at the conference. Thanks, I enjoyed the presentation.
LikeLike
Bill, Janine says to expect them (and the 2017 presentations) by 4/17/19
LikeLike
Jim – One of the things that really jumps out at me is how few of your ancestors are represented on the ahnentahfel list in the cluster summary. My hope would be that an advanced genetic genealogist like yourself would show broad inheritance across many 4-6th great grandparents. But if your results are normal, you’re showing much more concentration in a smaller number of ancestors. I map my chromosomes, along with other close family members, to try to break through genealogy brick walls. But that won’t be easy to do if I don’t have matches for many of them….
LikeLike
Rich – An interesting observation. I can assure you that I have DNA segments spread over the majority of my ancestors – as it should be.
What you are seeing is a relatively small slice of my “body of work” – I have a spreadsheet with over 14,000 different Matches from 6 companies, all in Triangulated Groups (TGs). These TGs cover over 98% of my 45 chromosomes and pretty much define what I got from my two parents. I’ve further determined the grandparent for 80% of my DNA. Yes, for some of these TGs I don’t any Match with a reasonable Common Ancestor (CA). There is a CA for that TG, I just haven’t found a cousin yet.
What you are looking at are my Matches from Ancestry, with 20cM or more of DNA – that exculdes out a high percentage of my 996 Hints (plus many other CAs I’ve found without Hints). This 20cM threshold is designed to capture 4th cousins (4C), 5C and some 6C. That’s focused mostly on my 32 3xG grandparents, plus some of my 64 4xG grandparents, and some beyond, etc. A number of the clusters, which are based on TGs, are only noted out to my grandparent or Great grandparent level – I’m sure I’ll find more distant CAs as I work on each one.
In the grand scheme, I had 156 Clusters – if my theory is correct, that would account for most of my 128 5xG grandparents, and some more distant ones. The issue I’m seeing is that I have not found enough cousins with shared segments at that level – period; and/or found them with robust enough Trees. I think I’ll learn more if I start ‘Walking the Clusters Back” even if I don’t have known cousins at that level.
What you tend to see with Ancestry Matches are well researched and established ancestral lines – ones that many people copy over and over. Some of my lines are fairly “narrow” with few children, not many records in burnout Virginia counties – not many people with them in their Trees – Lord knows, I’ve searched Trees for them… The DNA is fairly evenly spread, the knowledge of those ancestors is not.
I hope you’ll see that the issue here is not in the DNA process, the issue really is finding Matches with both Trees and DNA segments. Oh what I could map if my 1,000+ Matches with CAs at Ancestry had segment info…. Jim
LikeLike
Super XXXX PS only good thing about my being unable to sleep due to leg cramps tonight is this email dialogue!!!
Sent from my iPhone
>
LikeLike
Thanks, I just got back from a 6 week vacation 5 time-zones away – I couldn’t sleep either, so I blogged!
LikeLike
Thank you for your reply.
If I have already narrowed down the choices to my 1xg-gpa’s branch (I am using only known cousins of his branch). If all unknown WILLIAM cousins share with me and each of my cousins…
Couldn’t I use a Network chart for myself and each of my known cousins? Each chart would use personal information for each of us and the shared DNA (cM and segments) of the WILLIAM cousins?
I realize this this type of chart does not distinguish between the DNA of Mr. and Mrs. But, would it be safe to say that Mr. and Mrs. WILLIAM were most likely my 5th great grandparents? GEDmatch would be best to use to verify…But, Ancestry does have trees😉
Thank you,
Mary T
LikeLike