
Progress Report – Observations…
Main benefits, so far:
- Impute Cluster Common Ancestor (CA) to other Matches in the Cluster – this let’s us focus on individual Matches – look at their Tree with a CA in mind, and/or communicate with the Matches and ask about a specific Surname or Ancestral line.
- Compare Cluster CA to ThruLines CA – if the same, we have reinforcing evidence; if different, the ThruLines CA may be wrong, or it may be correct genealogy, but the Match has another CA linked to the DNA (and the Cluster).
- Link some Clusters (and the CA) to a Triangulated Group (TG) – this will strengthen the evidence of the Ancestral line of a TG. Often the Cluster CA is more distant than the CA found in TGs at 23andMe, FTDNA, MyHeritage or GEDmatch.
- As the threshold decreases, there are more Matches included in the Clustering process, and those Matches tend to have more distant CAs with us. Clusters will start with only 2C and 3C; and grow to include 4C and 5C, etc. We can see the Walking The Cluster Back happening within each Cluster. Eventually each Cluster will begin to show several generations of CAs – they should all be on the same Ancestral line [if not, check with the correlated Clusters]
- Clustering reduces the range of possibilities. If a Cluster has a CA of A18 [Ahnentafel number for a specific 2xGreat grandparent = father’s father’s mother’s father], there are only two possibilities for the next generation: A36 and A 37 (although a Match may share a CA another generation back: A72, A73, A74, or A75). If a new Match in the next (lower threshold) Cluster run has CA = A74 – this is reinforcing evidence. If the new Match has CA = A88 – something is amiss [check for another CA, check for a correleated Cluster which is A44, or A176, etc.]
Main issues, so far:
- It’s been hard to specifically find Clusters which split into two Clusters a generation further out. Many Clusters have included CAs which span several generations on the same line. I’m inclined to “go with the flow” [accept the Clusters with CAs on the same line]; and not try force Clusters into a “genealogy Tree” structure. The data is just too variable. Maybe when I get down to a 6cM threshold, it may play out that way – but, I have a feeling the vagaries of random DNA will make that a wild goose chase.
- Several BIG variables combine to give us trends, rather than a uniform picture/pattern:
- Our Ancestry (size of families, documentation, probable NPEs at some level, etc.)
- Our random DNA from different Ancestors
- Which of our cousins have DNA tested.
- Homework is needed – Clusters can be formed, but some genealogy is needed to identify the CAs. I recommend building a Tree of Ancestors out 7 generations, wherever possible – with that AncestryDNA will find ThruLines CAs for you. Enter those CAs (or their Ahnentafel) into the Match’s Notes, so that information will be available in the different Clustering runs.
My status so far is summarized in this Table of different Cluster runs:
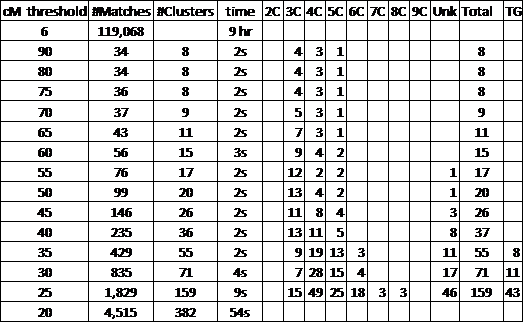
The first column shows the decreasing thresholds I used (basically every 5cM) – the top line is the original download: 6cM threshold, 119,068 Matches (and all their Shared Matches) which took 9 hours and is in a .txt file.
The # Matches and # Clusters are for the various cluster runs – which take negligible time to produce an Excel Cluster report.
The 3C, 4C, 5C, etc column show how many Clusters I got with CAs at those levels. (There were some 2C, but they were in Clusters that also had 3C – I counted each Cluster with the most distant cousinship which had a consensus.)
The larger threshold Clusters had multiple TGs in them. Beginning about at the 35cM threshold, some of the Clusters started showing a single, or consensus, TG – so I counted them.
Starting after the 45cM threshold, the number of included Matches about doubled with each decrease of 5cM in the threshold, and the number of Clusters began increasing dramatically. This means the amount of work for scrolling down the entire report, analyzing the data in each Cluster and determining the consensus, also increased a lot. Sometimes the CA and/or TG of a Cluster is very clear; sometimes a Match’s correlated Clusters must be reviewed and the Match assigned to another Cluster. And all new Matches need to be “Tagged”; and often other Matches need to have their “Tag” adjusted [what I alluded to in the Iterative WTCM Process], as new Matches and their new information are added to the Clusters.
The good news is in the TG column – where about 1/4 of the Clusters (and CAs) can be linked to TGs [I have TGs for over 300 Matches at AncestryDNA].
More good news: The Shared Clustering program, below 20cM, will first Cluster on the 4,515 Matches, basically retaining the 382 Clusters constant, and then go back and add in the new Matches. Therefor, all the Matches below 20cM (including about 300 with TGs, and over 1,500 with CAs) will be added to the existing Clusters, and very probably push the Cluster CA out even farther and add the a TG to many of them.
Note the trend in the 35, 30 and 25cM Cluster runs to more distant cousinships. As I find the time to analyze the 20cM Cluster run, and then runs at 15cM and 10cM, I expect this trend to continue, giving me many more CAs in the 6C, 7C and 8C range. Of course these are all clues, but I believe they are very strong clues. Time will tell as I investigate each Cluster/CA/TG more deeply.
[19F] Segment-ology: Walking The Clusters Back III by Jim Bartlett 20191214

You are correct with “along the same line” – that is entirely possible, and, in fact, is Walking The Cluster Back within the Cluster. The number of Clusters will pick up as you go down. Jim
LikeLike
Pingback: A Unified Theory of Genetic Genealogy | segment-ology
I am finding a similar situation in my own data, as I walk my mother’s clusters back. My first limit for her was at 60 cM, which broke out her matches into 3 clusters. In each cluster, there was more than one CA, but along the same line. Cluster 1 had ancestral couples (Ahnentafel 14/15, 30/31, 60/61) in cM ranges from 60 – 260. 14/15 were her only great-grandparents born in the US, and her matches at Ancestry skew heavily to those 2 lines, likely due to large families, deep U.S. roots and numerous cousins tested. The number of clusters is growing slowly… at 25 cM threshold, just 25 clusters, but some are huge with what I would call “subclusters”.
LikeLike