
Common Ancestor Spreadsheet
By popular demand, here is a portion of my Common Ancestor Spreadsheet:
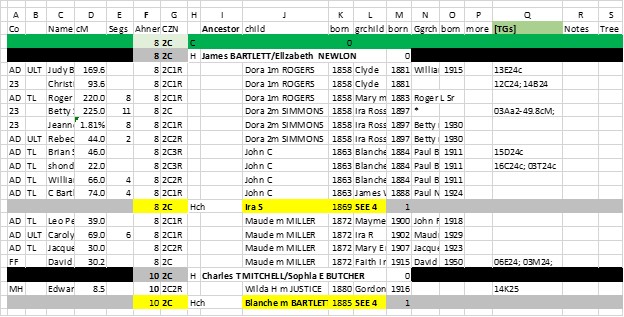
I’ve added letters at the top of each column for ease in describing them:
A – Initials for the testing company – if a Match tests at multiple companies, I list them for each one.
B – This indicates if the Match also has a ThruLines (TL) or UnListed Tree (ULT) or Theory of Family Relativity (ToFR), etc. Perhaps a quirk of mine in data collection, but this lets me sort the spreadsheet to select all the TLs, for instance, and compare with the AncestryDNA TL list for completeness.
C. The name of the Match – may also include the Admin or Point of Contact
D. Total cMs
E. Number of Segments
F. Ahnentafel number for the MRCA
G. Cousinship
H. A code for Headers (C is a Green separation for each generation; H are my Ancestor Couples; Hch are my Ancestors who are a child of the Ancestor couple – also highlighted in yellow; Also Hm is a row for a 2nd marriage of an Ancestor – usually with a note that Matches who descend from subsequent children would be half-cousins (use the marriage year in the K column)
I. Ancestor Couple
J. Children of Ancestors – these are the children the Matches descend from – daughters are noted with the surname they married (important to identify grandchildren, etc.) Each Ahnentafel should have a row for my Ancestor (and birth year).
K. Birth year of children
L – O – like J and K
P. This is just one column to add the rest of the descendants down to the Match, if you want to do that (I’ve deleted my entries here as it gets too close to living people)
Q. Triangulated Group IDs – I add a “c” when the TG is implied from a Cluster or consensus among Shared Matches.
R. Add any notes you want – some of mine includes notes when a Y-DNA or mtDNA (testing) path is in the line of descent; or if the line of descent is “iffy”, IMO; or TL was wrong, and this is the fixed/correct version; etc. (whatever you want)
S. Tree URL – this is often very handy to review and/or to quick get back to the Match.
I cannot emphasize enough that spreadsheets are very personal, and you should exercise your own judgment to adopt this one to your own preferences, and to add any other columns you want (realizing that each additional column is more work to maintain).
Here are some additional columns from my spreadsheet which I occasionally use:
Hg – Haplogroup (Y or mt) if it applies to the Match and is important to me
Gm – GEDmatch ID# for the Match
Related – I often note when two (or more) Matches are closely related to each other (this cautions me to “dilute” the value of, say, two children or siblings, as they do not add to any consensus.
MyT – I note in this column (y) if I’ve added this line of descent to my main Tree at Ancestry – it helps me get more ThruLines…
Other – I note in this column any other MRCA Ahnentafel this Match is related to me on – the Match is in my spreadsheet for each such additional relationship (it remains a task to figure out which MRCA goes with the Shared DNA Segment).
Email – email of the Match
The main purposes (for me) of this Common Ancestor Spreadsheet include:
1. Document (in one handy place) all of my Matches with MRCA
2. Use the Family Group Sheet format to check the accuracy of Match descendants against my own Family Group Sheets and/or genealogy research.
3. Determine closely related Matches (this sometimes results in a good communication thread that shares info, draws in other research. and maybe more interest in DNA testing.)
4. Tracking the TGs vs MRCA; particularly with respect to the “Rules”.
Feel free to post a comment about any additional use you see for this spreadsheet; and/or any improvements or drawbacks…
[15K] Segment-ology: Distribution of TGs – Part 4 by Jim Bartlett 20211013

I like the idea of keeping ones identified matches and MRCAs in such a spreadsheet. I‘m not sure how one would record double cousins, though. I have 3C matches who share two sets of my gg grandparents with me. Jim, how do you record such multiple relationships? List them twice, under both sets of gg grandparents or have a separate group for such matches? What about situations where there is one set of MRCAs but other CAs farther back but on a different line?
LikeLike
Emily,
The CA spreadsheet is about CAs. It’s a tool to organize your data. So I list a Match with each and every CA – for two reasons:
1. It fills out multiple Family Group Sheets – adding evidence for each one; and letting you see interrelationships within a family.
2. Each segment of DNA comes from only one ancestor line down to you. Eventually you want to figure out which CA passed down the DNA. With multiple segments, it might be that each of two CAs is linked to different segs. In other words – some of the rows in a CA Spreadsheet, will turn out to not be from a Shared DNA Segment (which is OK) or that the Match is genetically related multiple way (also OK). This is easy to spot if you have some Matches with TGs. Example and CA on Ahnentafel 40 (2>5>10>20>40 – on my father’s mother’s side) could not come from a TG like 08F36 (3>6 being on my mother’s father’s side). So I would highlight that as NOT a genetic link – but keep it in my spreadsheet, so I don’t trip over it again, and to highlight that there must be another CA with that Match (and maybe a small segment for the CA I know).
Jim
LikeLike
Hi Jim. This series has been great! I am just getting started with segmentology and genetic DNA in general, so this has been extremely helpful. I have a few questions if you don’t mind.
1) For someone just starting out, it looks like the recently released Autosegmentation (with triangulation) program at GEDMatch would be a great jump start. It appears to use your spreadsheet format as output. Am I understanding that correctly? Any downside?
2) Have you posted any tips on keeping your master sheet up to date as more matches appear on the various sites?
3) Do you ever use pivot tables to analyze the master data? I’ve found that when confronted with a large dataset, a pivot table can be useful for slicing and dicing.
Thanks,
Par
LikeLike
Pat, Good questions – I’ll give it a go…
1) Yes, a good start. In general, I’ve not found an “auto” program to be 100% correct (but I have also made mistakes with my manual system). This one appears to be very good. It’s a start, and you’ll want to add many more Matches to it – any errors should be revealed as you add new Match-segments.
2) I do it in glumps, maybe every few months (add in close Matches as soon as you find them – by hand). I use two methods: a) type in by hand, with a few Matches; b) download the who list from a company, arrange columns to match your Master, add all the matches to your Master, sort by name and delete the duplicates (also delete any segments that are below your threshold)
3. I do not use pivot tables – If you find a process using pivot tables that is helpful, please let us know.
Jim
LikeLike
Thank you for this spreadsheet post. It will prove to be very useful for me.
LikeLike
Rod – Great – thanks for your feedback. Jim
LikeLike