
A Segment-ology TIDBIT
Genetic Genealogy is a very iterative process – particularly at AncestryDNA. The more you find out, the more the AncestryDNA Tools feed back new clues to you.
Here is an overview:
Genetic Genealogy Process at Ancestry DNA
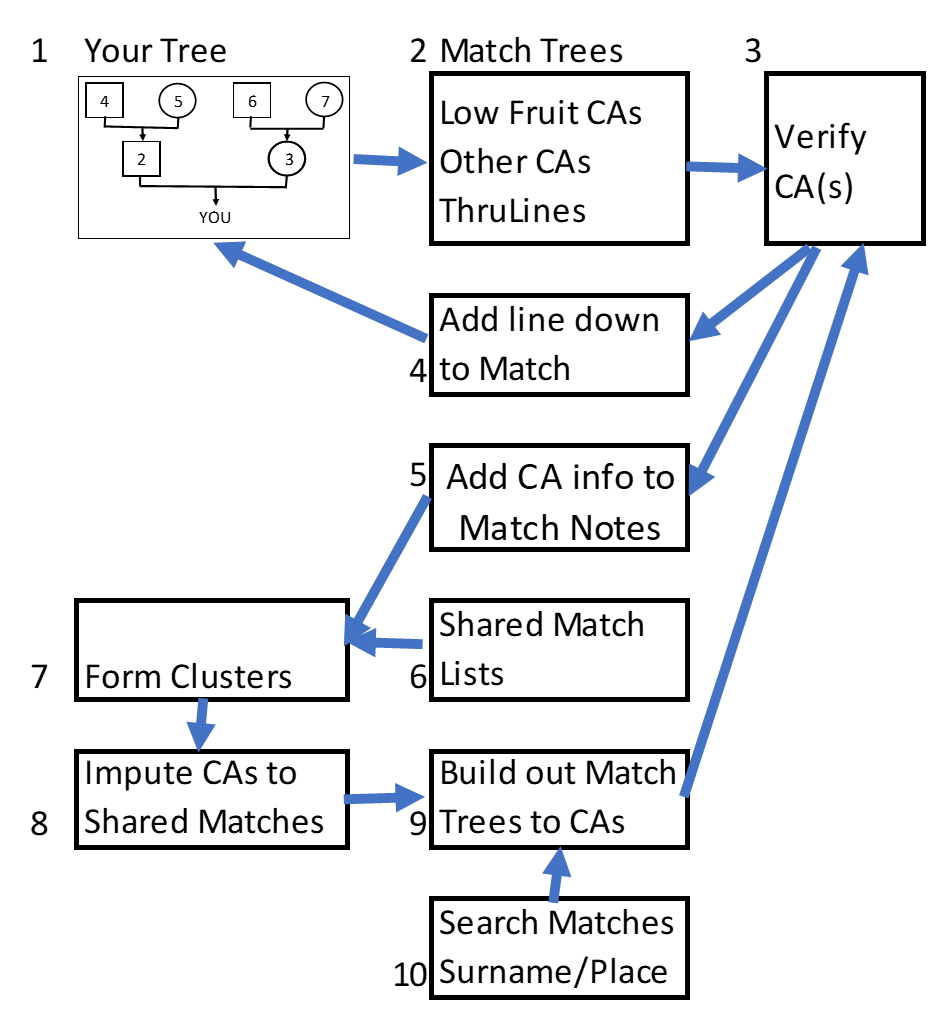
Let’s take it step-by-step and see how it snowballs…
1. First build your Tree and link it to your DNA results. This is very important because AncestryDNA keys off of this information, and your DNA Matches, to provide you with strong clues. Even if you don’t know much about your ancestry, list yourself and the Ancestors you know with their birth/marriage/death dates/places. Even one or two generations can often link you into AncestryDNA’s giant Tree. Focus on adding the Ancestors you know. Later you can add pictures, records, children, etc.
2. Work your way down your DNA Match list (your closest Matches are at the top of the list) and try to determine how you are related to them. Find the “low hanging fruit” first. Continue to work on other Close Matches who have Trees. Check out any/all ThruLines. You are looking for Common Ancestors (CAs) with your Matches.
3. Verify! All the CAs you find should be verified by you – both the individual Ancestors as well as the line of descent down to the Match.
4. When you are satisfied that the Match really descends from your CA, add the line of descent and the Match (as a living person) into your Tree. I find that this step tends to generate more ThruLInes. Note that ThruLines finds lines and Matches in Private Trees – something we cannot do.
5. Add the CA information to the Match’s Notes. This keeps track of it for you, AND, since the Notes are visible in a Shared Match List, it helps build consensus for CAs in Clusters. The information you put into the Notes is very valuable. More on Notes in this blogpost here.
6. For each Match you are working on, always look at the Shared Match List. The Shared Match Notes will tell you when there is a consensus; they add confidence as you add more and more notes pointing to the same CA.
7. Also use the Shared Match Lists to build Clusters – either automated Clusters including many of your Matches or a Manual Cluster focused on a few Matches for a particular objective. See my DIY Clustering blogpost here.
8. Clusters have been shown to group on an Ancestor. If you see this congruence in the Notes, you can input a *clue* in the Notes of other Matches in the Cluster. (The *clue* is not rock solid evidence). This includes Matches with No or Private Trees. The Clusters and Notes often provide an Ancestor “pointer” for these other Matches – which is sometimes the only information you have about them.
9. For Matches with *clues* in their Notes, see if you can build out their Tree to the CA. Building out Trees is one of best genealogy Tools, and it’s somewhat more efficient when you have a target CA (with known surname and timeframe and location). At this point, cycle back to Step 3 and verify the line and Step 4 add it to your Tree and Step 5 add the information in the Match’s Notes.
10. Additionally, you can search your Match list for Surnames and Places. See my blog post here. This search returns a list of your Matches, who share DNA with you, and who have a large enough Tree which includes the Surname in their Ancestry – that’s a pretty efficient method of finding CAs. You might have to build out the Match Tree, and you’ll need to do Steps 3, 4 and 5 again.
This whole process adds information to your Tree and to the Match Notes. These in turn lead to more ThruLines CAs, which continues this iterative process.
[22BI] Segment-ology: It is Iterative TIDBIT by Jim Bartlett 20220731

Mr. Bartlett….thank you for these articles on clustering. It has helped me to understand how they are broken down. You had mentioned using DNAGEDcom as a clustering program, but do they accept Ancestry.com’s testing data? If not, what company do you use to cluster your DNA matches? It would be helpful if DNAGEDcom did as like you mentioned using the notes on each match is helpful in clustering one’s DNA matches. I have a lot of notes on my Ancestry.com matches that I could use in clustering 🙂 Thank you in advance–Hiliary
LikeLike
Hillary – please see my WTCB blogposts and the comments. The answer is yes, and their gathering program also gathers the Notes for each Match – this is a huge benefit to have all of that data in a single spreadsheet: think of the searches and sorts… Jim
LikeLike
Thank you!!! I appreciate your help.
LikeLike
Hiliary – there is also a DNAGedCom user group on facebook – the inventer, Don Worthen, fields questions there…. Jim
LikeLike
Pingback: Wlaking the Clusters Back (WTCB) 2022 | segment-ology
Pingback: Best of the Genea-Blogs - Week of 31 July to 6 August 2022 - Search My Tribe News