
My recent blogpost on Walking The Clusters Back (WTCB) is here. This is an advanced topic and process which involves homework before you start. The idea is to start with your closest known Matches in several Clusters (maybe 5 to 10). Then gradually decrease the lower cM Threshold in order to “follow” the known Ancestors in your Tree; back to Most Recent Common Ancestors (MRCAs) with Matches; and impute these “Root Ancestors” (your parent, grandparent, etc) to the other Matches in each Cluster. The linked blogpost provides a spreadsheet template. In practice the initial Cluster runs are fairly easy, but the number of Matches roughly doubles with each run. It soon becomes a time consuming, head-scratching, process (take regular breaks….).
Bottom line: It’s working very well – the Clusters in each new “run” carry over Root Ancestors from previous runs, and the addition of new Matches sometimes extends Root Ancestors.
My plan is to post several more blogs about the details of the process, and the insights I’ve gained doing it. But in this post I want to provide you with two tables of my experience, so far.
1. Summary of Cluster Runs:
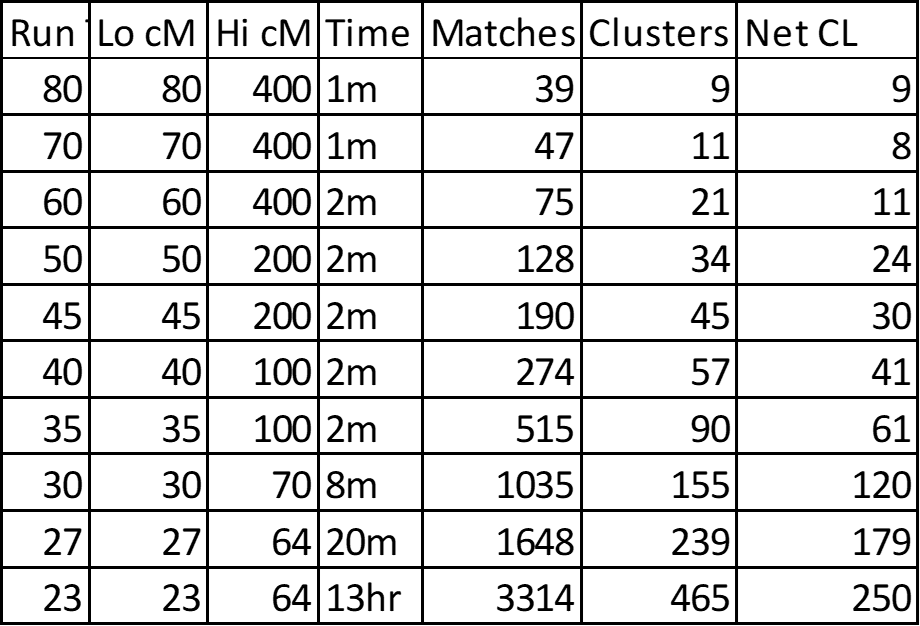
I title the Cluster Run by the Lower cM (Lo cM) Threshold. You can see I started with 80cM and reduced by increments down to 23cM. I also adjusted the Upper cM (Hi cM) downward to cull out the closest Matches which become confusing. The Time column is the time it took DNAGedcom Client to produce the 3 data documents (after the initial gathering process). These different Cluster Runs resulted in the number of Matches and Clusters shown. I rolled up some of the very small Clusters – usually, but not always, into the main Cluster in a Super Cluster. At the end of my analysis, I had the number of Clusters in the Net CL column.
I note that although the *average* size of Clusters grows, slightly with each decrease in the lower cM Threshold, this hides that fact that a number of Clusters are in the 50-100+ range. The average stays low because there are a lot of 3-10 Match Clusters. The 250 Clusters in the 23cM run, is approaching the 372 Triangulated Groups I have already established over all of my DNA. My TGs also range from small to large groups…
2. Listing of Root Ancestors in Clusters:
G2 is the parent generation of Root Ancestors – always a 2 or 3; G3 is the grandparent generation (3, 4, 5, or 6); etc. The Ahnentafel numbers represent my Ancestors out to, but not including, a consensus Most Recent Common Ancestor (MRCA) couple between me and the Matches in each Cluster. Many of these MRCAs are from Ancestry ThruLines and were validated by me (I find about 5% of my ThruLines hints are incorrect and they are not included in my Notes or in these Clusters). I’ve done the “homework” of including all the validated ThruLInes MRCAs in the Match Notes, which makes the above List possible.
The above 228 Clusters are about 90% of my 250 net Clusters for this 23cM run (the other 10% don’t have a clear consensus – these cases are usually resolved in the next Cluster run).
The Root Ancestors shown above are a huge benefit in several ways:
A. finding and validating more MRCAs with Matches in each Cluster – there is a clear focus on who I’m looking for, and generally where and when.
B. identifying MRCAs that do not “fit” – they stick out like sore thumbs, in that their RAs clearly do not match the consensus. Sometimes this is resolved because the Match is related to me more than one way, and another way does “fit”. In all these cases I need to revisit the MRCA conclusion. This is a significant Quality Control “opportunity”.
C. Identify other problems: MPEs, ThruLines Potential Ancestors, hypotheses, etc. The RAs in each Cluster really narrow down the alternatives.
So this is a SITREP (Situation Report) of where I am now. The 20cM run is next – adding over 2,500 new Matches (many with MRCAs) – this may take weeks to sort out. Then I will take perhaps an additional 1,000 ThruLines under 20cM and see if I can manually include them in Clusters (if they have Shared Matches). And along the way, I want to post more details and insights about this WTCB process.
[19Na] Segment-ology: WTCB SITREP by Jim Bartlett 20220821

Pingback: Segment Data for Ancestry Matches 2 | segment-ology
Is DNA Gedcom a free site? Your clustering technique looks interesting. It would be great to be able to work clusters instead of who are these people.Debbie
LikeLike
No – it’s a subscription site. Do the “homework” first and the sign up for 1 month for $10 and run the download, then the individual Cluster reports. All doable in a month.
LikeLike
Both this and the previous post provide a good lot of detailed instructions to work from. When I have time, I am going to see what I can do with this regarding my line that runs out of records the earliest, but does have a decent number of people who match my known 3Cs on that line.
LikeLike
A fantastic bit of work, Jim. Great logic and very well presented.
Thank you!
LikeLiked by 1 person