
A Segmentology TIDBIT
UPDATE: AncestryDNA has issued a cease and desist order, and this process is no longer available to download your Matches. Sorry about that.
That is download: all your Matches, a hyperlink [to their Page as a Match to you], Shared cM, Shared Segments, Tree Type, Tree Size, Common Ancestors [per ThruLines], a tic for each Dot and Star, and your Notes! This fast download does NOT include your Shared Matches, which may take days to download.
Here’s the process:
- Before running this program, I set up a separate folder with todays date [e.g. 20200409] for each download; the Shared Clustering program will give you a chance to select this folder and to rename the download file.
- Download the Shared Clustering program. See my review of this program here. The link to upload this program is: https://github.com/jonathanbrecher/sharedclustering/wiki
- Click on Download TAB
- Enter your Ancestry user name and password [stored on your PC only]
- Click on Sign In
- Select your Test (if you have access to more than one)
- Click the button for Fast but incomplete
- Open Advanced options
- Lowest centimorgans to retrieve: 6 [this includes all of your Matches]
- Lowest centimorgans of shared matches: 4000 [this means don’t download any Shared Matches]
- Click on: Get DNA Matches
Here’s a picture of the message when the download is complete:
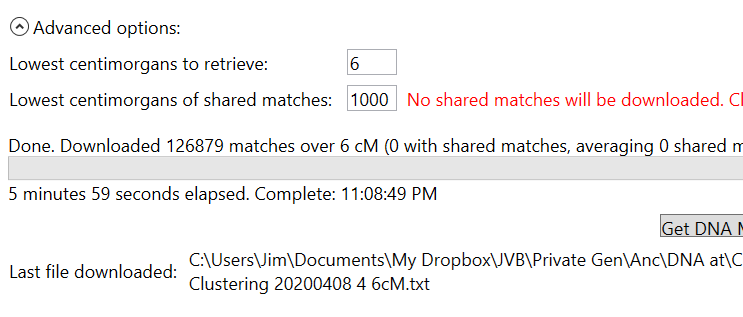
So 125,000+ Matches in 6 minutes – your results may vary.
After the download, Export the downloaded txt file to Excel. Click on the Export TAB, and follow the prompts to create an Excel file – takes about 4 min.
You can then use/manipulate the Excel file. You can sort on any field, and you can edit any Notes and then Upload those revisions back to AncestryDNA. I use this as an opportunity to do a Quality check of my Notes, and to insure I have a Note for each Match with a ThruLines Common Ancestor. I find it’s much easier to edit Notes in the spreadsheet, than to jump around to each Match at AncestryDNA. NB: Don’t edit Notes in AncestryDNA when you are also editing Notes in the spreadsheet. If you do any edits in AncestryDNA, you need to do a new Download (it only takes 10 minutes!)
[22AS] Segment-ology: Download Your AncestryDNA Matches in 10 Minutes!
TIDBIT by Jim Bartlett 20200409 EDITED 20200808

Why am i only seeing this now 😦 I just downloaded My Heritage data and through it would be great to compare both.
LikeLike
Karen,
This was an old post. Ancestry has asked the Clustering programmers to NOT “scrape” their pages any more. You can try them, but it may not work.
LikeLike
Only just found this way of clustering my Ancestry matches so thank you for writing this blog so I could find this amazing tool. I am getting more and more annoyed with AncestryDNA, if they don’t provide the tools we need then what do they expect? As an aside I have been copying and pasting my matches and shared matches manually using the Google Sheets spreadsheet from http://www.dataminingdna.com, but I still feel that even when just browsing my distant matches quickly, going back and forth in and out of matches, Ancestry has introduced code on their site to “kick” you out of your match list that I can only think is a preventative measure to scraping programs (however whatever code they put in it can always be circumvented by just changing the scraping program.
I can understand why Ancestry doesn’t want everyone hitting their site with these kind of programs, but having viewed how much memory their matches page runs under on my laptop it just is not at all well designed, almost not fit for purpose, unless you are only looking at your top matches, the pagination they seem to employ just doesn’t work. So I had all of the shared matches for my grandpa, who is 103, copied out, and was looking for a way of clustering them, found this, so it has saved me having to write something for myself to analyse them, further than just adding dots based on groups shared matches were in, and seeing if you can spot common patterns in the attached trees. This gives me so much more. The code for this app was written more than 3 years ago and Ancestry still doesn’t have any tool that allows you to export matches and their shared matches, and doesn’t want to work with 3rd parties that provide this service for other sites. There’s so much they could easily do to help this and other things, but just don’t seem interested. I’m so glad I don’t have to rely on them anymore!!!
LikeLike
Matt – There are lots of things that don’t work the way we might prefer. I try to focus on what we *can* do – and I try to pass that along in this blog. AncestryDNA does listen to their customers, and I encourage you to pass along your requests to them directly.
Glad to see you using spreadsheets. My title for this post should have been: *Updating* Your AncestryDNA Matches in 10 Minutes, because the initial run takes a while. You might have read my blogs about the four spreadsheets I keep. Plus the Walk-The-Clusters-Back process with spreadsheets – takes a while, but it let me link many Clusters to Triangulated Groups. Jim
LikeLike
Ancestry is doing a massive delete of DNA matches with 6-8 cM with virtually no warning. This may appear inconsequential but for someone like me whose father was quite old when I was born, those matches are essential. They may be the last DNA links to older generations. I have had amazing success using them as tools in locating clusters of my family around the world. I didn’t know how to download them until I saw this blog. Unfortunately in addition to giving no warning to speak of Ancestry is also cutting off the possibility of download using the link you provide. Please help. What can I do?
LikeLike
Linda,
The short answer is to “Dot” the small Matches (under 8.0cM) that you want to keep. Or “Star” them. Or put a Note in the Notes box. Or send them a message. The fastest/easiest is to Dot or Star them. At Ancestry, select your DNA Matches list. Then click on Shared DNA and select the Custom centiMorgan Range to get only the small ones. I would also select Public linked trees, so you only get Matches with Trees. There is no way to now download the AncestryDNA Matches any longer. Jim
LikeLiked by 1 person
Quick (and possibly ‘dumb’) question here… ‘Fast but incomplete’ button? On what screen do I find this? I’ve gone through every screen I can find. Thanks.
LikeLike
Alan, GEDmatch has changed their menu – there is only one program now to upload your data: Generic uploads – remember this applies to your raw DNA data. Thanks for your feedback. Jim
LikeLike
Pingback: Download Your AncestryDNA Matches in 10 Minutes! | Monterey County Genealogy Society
Jim, this is totally ADDICTIVE and great! I downloaded it late yesterday afternoon, ran my matches, and was still making discoveries hours and hours later–like 2 AM!
LikeLike
Karen,
Glad you liked it. I like to sort the spreadsheet on Common Ancestors, and see how many children of the CA are covered.. This sort also lets me check to see I have something about each of these Matches in the Notes box. That way, when I’ve looking at a Cluster, I can see if there is a consensus for it (or not). Often I can readily tell which side a Cluster is on – sometimes which grandparent or great grandparent, just from the CAs in the Notes. This helps my Matches too, because I can tell them that they are related to me on my father’s mother’s father’s side (for example), which really narrows down the are of my Tree to search (for me and each Match in the Cluster). Jim
LikeLike
Jim, my brother uses “all Apple products.” If I send him just the spreadsheet, will he be able to use the various features of the SS within a Mac version of Excel?
LikeLike
Karen,
Yes, that should work. I run the program and get the spreadsheet. From then on I leave the Shared Clustering program off. If I make changes to the spreadsheet, I can then save a copy of the spreadsheet to the same folder in my spreadsheet where the download is, and upload all the changes back to Ancestry. So your brother could use the spreadsheet, make changes and then give it back to you for upload. Jim
LikeLike
Jim,
just started using Ancestry clustering this week. I have 1400 rows of 20cM+ and 61 clusters created. What determines what becomes cluster 1, 2, 3, that is what is the order from1 to 61 mean ? I can spot my grandparents and great grandparents but they seem randomly positioned in the 61. Thanks
LikeLike
Jim,
Randomly is the key word. The clustering algorithms were borrowed from advertising and business and science to group lots of data points which were linked to each other. Sometimes you can jostle your data a little and get a different layout 1-61.
LikeLike
My download of 88,000 + matches took 3 hours or so. The endogamy thing seems quite inaccurate. I have a lot of Cajun matches where most link to me via multiple lines. Yet the tool said I had none.
LikeLike
John, did you set the second cM box [cM for Shared Matches] at 1,000 or 4,000? It needs to be high enough that you get the red warning message that you won’t be able to cluster that data.
LikeLike
No I didn’t. I’ll try again. The funny thing about my tree is I can find 6th cousins with 15+ CM’s.
LikeLike
John, Matches below 20cM won’t show up as a Shared Match; but Matches below 20cM can have Shared Matches (all 20cM or higher). I have 6cM Matches who have Shared Matches.
Jim Bartlett Sent from my iPhone DNA blog: http://www.segmentology.org
>
LikeLike
Does this program work on a Mac Pro?? I don’t see any reference on the Brecher website or yours.
Thanks, Arthur
LikeLiked by 1 person
I don’t believe it does, Jim
LikeLike
Arthur, Maybe use someone’s PC…
LikeLike
Jim, In your picture of the message, it shows “1000” lowest centimorgans of shared matches instead of the “4000” that you recommend under instruction no. 10. That will cause those of us that are not paying good attention to end up with a download of over an hour, instead of 10 minutes. I had to abort the first download and then I figured it out. Hopefully not too many folks will make the same mistake.
LikeLike
Jim, In my DoD presentation days, we used to say consistency was a greater virtue than accuracy:>j In the Shared Clustering documentation, it says pick a value that is more than any Match. 1,000 works for me, but 4,000 would preclude children or parents. I just tried it again using 4,000 and it still gave me a download in under 5 minutes. Not sure why it didn’t work for you. Jim
LikeLike