A Segment-ology TIDBIT
Automated Match Clustering involves large spreadsheets; selecting max and min thresholds; downloading data; using third-party tools; and then analyzing the clusters. Is there a different way to Cluster AncestryDNA Matches? I think there is… Do-It-Yourself Clustering.
I think we can select a Match and then look at our Shared Matches and then, often, see a trend or pattern among them. If we’ve used the Note boxes liberally (see below), we might see known Common Ancestors (CA) among the Shared Matches and/or a known Triangulated Group (TG) among them. Note that we sometimes know one of these Building Blocks (CA, TG) without knowing the other – that’s OK, they are both important clues that are “pointers” to a Cluster.
So… in the Notes for each AncestryDNA Match, we select some notation to indicate what this trend or pattern is. This notation would be the tentative “Cluster ID”. We could use a Surname [PLUNKETT]; or a Couple [PLUNKETT/HAM]; or the Ahnentafel for this couple [104/105] (or just the shorthand version: 104 – see a CA ID method here). Or, for Matches who have uploaded elsewhere, and we know the DNA segment(s), we could use that data (see one method, the TG ID, here). Feel free to use whatever system works for you to identify which Cluster you feel pretty sure about for this Match. If it’s not clear, just skip this Match and come back later (we’d do this a lot for Matches with Private or No or skimpy Trees). Note: I believe each Cluster is based on an Ancestral line. Clusters around a closer CA will probably have multiple TGs; a more distant CA will tend to have one TG.
A real aid in this process is MEDBetterDNA. It’s a Chrome extension, so you must use the Chrome browser (free). It has several features but the critical one here is that you’ll see all your Match Notes all the time (no need to click on the little “page” icon). Google MEDBetterDNA and use checkbox: “always show Notes”. It REALLY helps in looking down a long list of Shared Matches. [BTW: it would be very nice for AncestryDNA to make this standard…].
To use this process, we also need to use the Note box – we need to enter any CA or TG we find for a Match. I started with all my Hints – each one had at least one CA. And, as I looked over all my closest Matches, I found more CAs. Sometimes I found Matches at GEDmatch, which I could Triangulate and link to AncestryDNA Matches, giving me a TG in the Note box. Whatever system you’ve used to find cousins with CAs or TGs, enter what you’ve found in the Note box. Then, for all Matches over 20cM, you’ll see those Notes when they are in a Shared Match list. The homework assignment here is to enter Notes for as many of your 4th cousins (4C), or closer, as possible. Note that you’d need this same data in order to get anything out of a Match Clustering Matrix spreadsheet.
Then, starting with 4C (saving closer cousins for later), and look at each Match. See if you can tell from their Notes and the Shared Matches’ Notes what the Cluster would be. Maybe there will be multiple choices. Whatever it is, enter your Cluster ID in the beginning of the Note box. Go to the next 4C Match and repeat. Skip any Match you want – this is an iterative process, and you may need to go through your list several times – I believe the Cluster IDs will “tighten up” – become more solid – with each iteration. At some point, even the Matches with Private/No/Skimpy Trees will have lots of Shared Matches with the same Cluster ID. Give that Match a Cluster ID, too!
After you’re satisfied with the 4C list, you can cycle back to the 3C list, and confirm that they are compatible with the trend of their Shared Matches. Each 3C may be associated with several Clusters. In fact some of your 4C Matches may have a few Clusters. This is OK – but multiple Clusters should be for adjacent ancestral lines which eventually converge (marry) at some level.
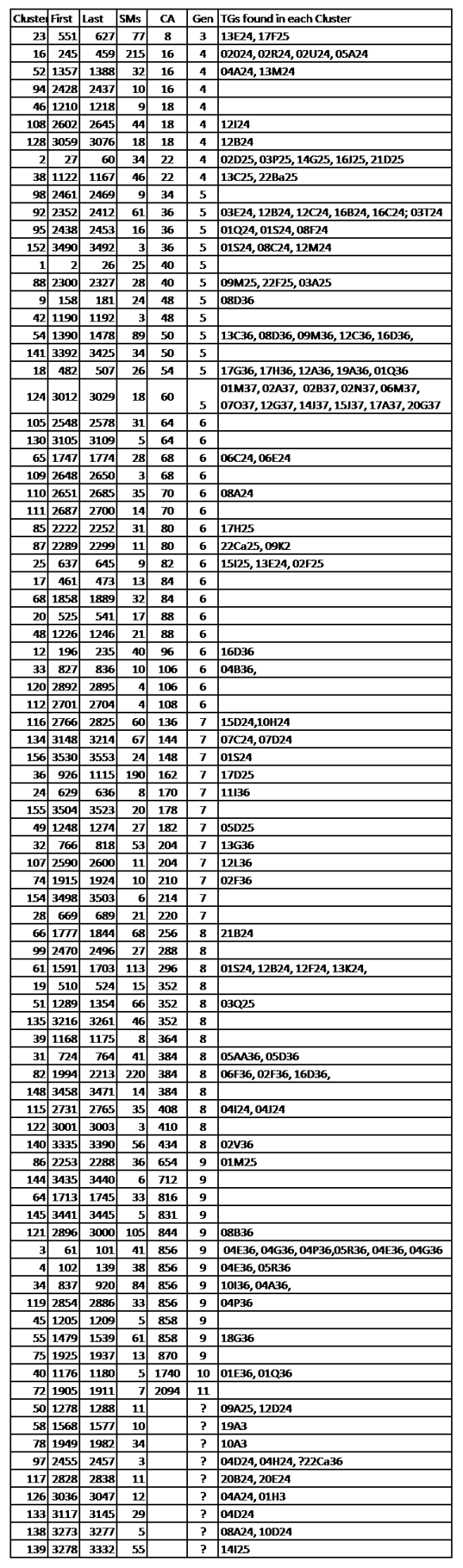
At this point, you can look at Matches beyond the 4C level. Many of my Hints with CAs are beyond 4C. Many of them will have Shared Matches (4C or Closer), and the Notes will point toward a Cluster ID. Although these distant Matches won’t show up in a Shared Match list, I’d still enter the Cluster ID in the Note box, just to keep track. You’d also need to list these separately – in a spreadsheet or on paper. However, if you put a hashtag, like #Cluster in your Notes, you can search on different Clusters. I just searched my AncestryDNA Results for #A0856 [my hashtagged CA ID] and 10 Matches popped up, including Matches with 6.3cM, 7.4cM and 13.2cM.
If I decided the above distant CA, #A0856, was a good Cluster ID, I’d enter #C0856 as the first entry in the Notes for all the Matches I thought were in that Cluster. Later, I could make a download and sort on the Note field to group all the Matches by Clusters. Or I could easily check my work against an Automated Match Clustering Program. Hopefully there wouldn’t be many differences.
The beauty – and benefit – of DIY Clustering:
- You can put a Match into more than one Cluster! Clustering programs have trouble with close cousins and multiple CAs/TGs – they don’t fit into just one Cluster. But what’s wrong with putting a Match into two or three Clusters if they really fit? Nothing – you are in charge with DIY Clustering.
- With Automated Match Clustering, you must have all your clues in place, up front. With DIY Clustering you can select which Clusters to work on first, and then get to the others later. Work at your own pace.
- DIY Clustering is primarily for AncestryDNA Matches, but you can also compare these Clusters with Match CAs and TGs from other companies. They should align and reinforce each other.
So, if you’d rather not use a Match Clustering program/spreadsheet, Do-It-Yourself. It involves entering Notes in a lot of Matches, but that is a good practice anyway. And the good news is you can adjust your Notes, and Cluster designations, as you go along. I actually believe we’ll get a better result with this DIY method, which we can easily tweak. I’m going to try it.
[22AD] Segment-ology: DIY Clustering TIDBIT by Jim Bartlett 20190218