This Part 3 will look at conclusions (what can we learn from all of this), and propose new spreadsheets to track all of your TGs or track TGs/Clusters through other children of our Ancestors (what we can do!).
Before I review the “Rules”, I want to focus set the stage on the Big Picture: Our autosomal DNA consists of 22 Chromosomes from each of our parents. And each of these Chromosomes has a mosaic of segments from our Ancestors. One analogy is an archeological dig with layers of artifacts – the deeper we go, the more distant (further back in time) the artifacts. Our DNA has a similar pattern. Each of our Chromosomes is composed of segments from our grandparents, passed to us from a parent. Going back another generation, each of our Chromosomes is composed of segments from our Great grandparents; and so on. Even if we went back 100 generations, we’d find that our Chromosomes were made up (completely) with DNA from that generation. This is not to say that every Ancestor in a generation contributed to our DNA; it is to say that some of the Ancestors in a generation contributed all of our DNA. And all of the crossover points are there if we can dig deep enough. But our DNA does not include “signposts” or markers that identify crossover points. Segment Triangulation is the only method I know to determine these crossover points and define specific segments from Ancestors (beyond Visual Phasing of grandparent crossovers). One drawback of Triangulated Groups (TGs), is that they are formed from available Shared Segments with Matches, and they are not formed at any particular generational level. However, we do know that each segment of our DNA came from an Ancestor – each segment represented by a TG came from an Ancestor. When we find a number of (widely separated) Matches in a TG agree on the MRCA, this is powerful evidence that the TG-segment came from that Ancestor. We can then map these TGs and MRCAs. In this respect, we learn that segment Triangulation (TGs) is essential to confirming our biological ancestry. We learn that the DNA is not scattered willy-nilly over our DNA. There are genetic guidelines – which I call “Rules” in this blogpost series. Our Chromosome Map should be in general agreement with these rules. And, perhaps in Part 4, I’ll try to outline how we can use these rules to predict much more.
So what do we learn/do with all this musing?
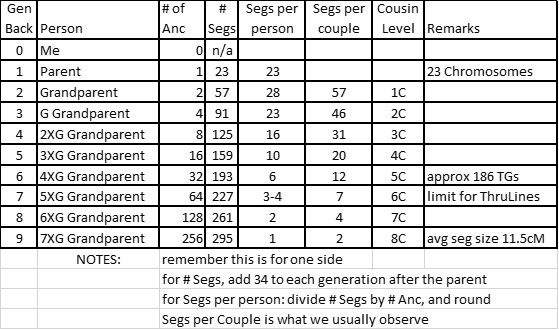
1. Learn: We can understand how TG segments originate in Ancestors – maybe 5 to 8 generations back – and pass them down to us, and our Matches. At each generation – coming down/getting closer to us – our Ancestors have more TGs – until our parents each pass down about 150-200 TGs to us.
2. Do: Use spreadsheets to track and analyze this growing amount of data… Examine closely areas that deviate from the rules.
LEARN
Here is a summary of our “Rules”.
-Rule #1: We can expect roughly the calculated numbers of TGs from each generation – an order of magnitude [See Table in Part 1]
-Rule #2: We can expect about 34 crossovers to occur per generation on each side.
-Rule #3: Shared DNA (with Matches) reduces by roughly 1/4 with each generation.
-Rule #4: We should not see Matches beyond 3C, with the same TG, descending from more than two children of a CA.
-Rule #5: The amount of DNA, and number of segments, in each generation, are not affected by external factors. [The number of TGs may be affected by the Matches you have.]
-Rule #6: The sum of the DNA contributions of all Ancestors at each generation will be 100%. This is a hard rule that is true at every generation.
-Rule #7: Each of our Ancestors will have all of the TG-segments both their parents had.
-Rule #8: A TG that subdivides going back, separates into a two smaller segments – one from each parent.
–Observation: Based on my 372 TGs, I estimate, using an 8cM threshold, most of you should get 150 to 200 TGs per side. They will range from small to large and span almost all of your DNA (there may be a few gaps – it all depends on the “coverage” provided by the shared DNA segments with your Matches.)
DO
I think we should track and analyze our TGs. My preferred method is with spreadsheets:
1. Master atDNA Spreadsheet – this is an “everything but the kitchen sink” spreadsheet for me. I include every IBD segment (over 7cM) of every Match – with segment, genealogy, and other information. I still plan, someday, blogposts about spreadsheets. This is a cursory overview. A spreadsheet is highly personal – I recommend you start with downloads from your testing company and add columns to suit yourself – mine is continually evolving.
Here are some of the columns in my spreadsheet:
a. Match info: full name, last name, company “name”, email, POC, company, Notes
b. Segment info: Chr, Start, End, cM, SNPs [from the companies} and TG ID (from me)
c. Genealogy info: Tree URL hyperlink; cousinship (e.g. 3C1R); MRCA couple surnames, side
d. Other info: GEDmatch ID, dates of communication, etc., etc.
e. Most of this info is from company downloads, the rest is typed in as I get it.
My spreadsheet has over 20,000 rows… including the following “Header” rows
f. 22 paternal and 23 maternal Chromosomes – Header/dividers
g. TG summary Header/dividers – uses earliest start location of TG; MRCA (per my judgment)
h. Alternate TG Header – to records alternate MRCAs for some TGs
Spreadsheet sorts – each of these sorts is a valuable tool for me
i. Alphabetical by name
j. Chr & Start – used to Triangulate segments (as they are added)
k. Side & Chr & Start – clearly groups all Matches in a TG – should have same MRCA
l. TG summary Headers, only, by Side & Chr & Start – to analyze MRCAs by generation [these headers have Ahnentafel numbers (in columns for each generation) to the MRCA].
m. This TG summary sort also allows an analysis with respect to Rules #1, #2 and #3 by generation.
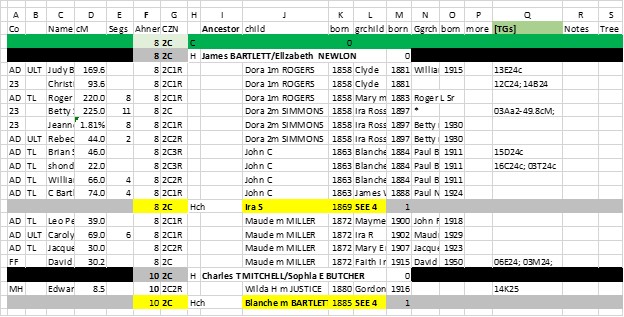
2. Common Ancestors Spreadsheet – this is a list of all Matches with Common Ancestors with me (now about 6,000 rows)
a. Match name, shared cM, cousinship, Tree URL; name/birth of MRCA descendants; Ahnentafel
b Any known TG ID or Cluster
c. A header row for each of my Ancestors (usually a couple)
This started with columns for Children of Ancestors; their birth year; and same for grandchildren – this info was typed in for each Match’s line of descent from the MRCA. I have since expanded it to include columns for remaining line of descent (and birth, down to the Match. For females I add married name; for example: Nancy m FLEMING to indicate succeeding descendants have a different surname (saves a little time and space).
Most of this info was from AncestryDNA ThruLines, but I have a number of rows for Matches from the other companies (and the TG info for them, which is like gold).
When this spreadsheet is sorted by MRCA Ahnentafel & Child birth, it looks like a series of Family Group Sheets for each MRCA family.
d. This makes it very easy to check against my Family Groups Sheets researched and developed over the past 45 years. I highlight conflicts in a mud color for further research and analysis.
e. This spreadsheet also has a column for for Potential Ancestors [POT ANC] (usually from Ancestry or MyHeritage]
f. For each Family Group, it’s also easy to check the range and average of Shared cMs for that family
g. Maybe most importantly for me, it allows me to see if there is a TG and/or Cluster thread in each family
h. I can also check for violations of Rule #4. This has already highlighted a few such violations – almost all of which led to an alternate MRCA with a much better “fit”.
i. All instances of a Match with multiple TGs and/or multiple MRCAs, must be adjudicated. A TG can only link with one ancestral line. This spreadsheet is a good tool for that analysis.
With this Common Ancestors spreadsheet I’m finding three things: a) each Ancestor does tend to have a consensus of Clusters and/or TGs; and there is the occasional outlier (this illustrates that just because you have shared DNA and an MRCA with a Match, it doesn’t necessarily mean the shared DNA came from *that* MRCA – there could be other MRCAs); b) there tends to be only a few groups (Clusters and/or TGs) in each Family Group – roughly in line with the table at the beginning of this blog post; and an occasional outlier of more than 2 children with the same TG (which indicates to me there is probably an issue – probably, also, where the shared DNA didn’t come from *that* MRCA).
3. TG Summary Quick Sheet – taken from my Master atDNA Spreadsheet, this just has a few columns, and I can fit all 372 TGs into 2 pages (maternal and paternal).
a. Columns: Chr; Start; End; TG ID; side; 8 columns for 8 generations of Ahnentafel numbers; MRCA Ahnentafel; MRCA cousinship; MRCA surnames
This Quick Sheet (1-page; front/back) is a handy reference – linking TGs to MRCAs and finding TG IDs for any segment. I include the Chr Headers (solid black) which highlight the TGs in each Chromosome.
I cannot over emphasize that spreadsheets are a tool, and you should adopt any spreadsheet to your own objectives and methodology. Don’t be afraid to add or delete columns or header rows.
Final thoughts for this Part 3 – think through the guidelines (“Rules”); and set up spreadsheets to help track and analyze your data. However, building and maintaining a spreadsheet to manage your Matches and Segments or Common Ancestors takes time – it’s not for everyone. Or… use whatever system you want – genetic genealogy is your hobby, and you are free to enjoy it however you want.
I might have a Part 4 with some more thoughts …
[15J] Segment-ology: Distribution of TGs – Part 3 by Jim Bartlett 20211008