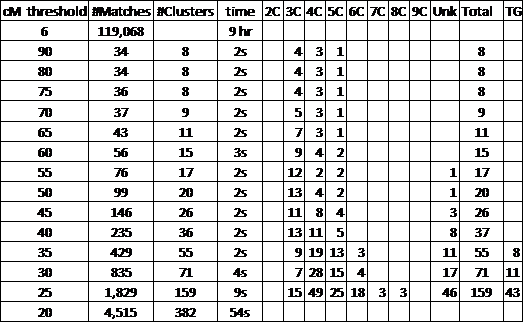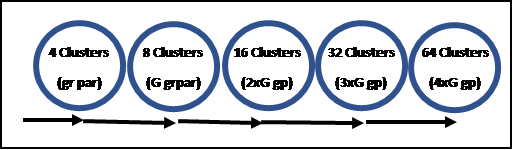A Segment-ology Concept
Overview
Walking The Clusters Back (WTCB) can be a fairly complex process, so let’s start with an overview of the concept.

Pick a Clustering threshold high enough to give us 4 Clusters – one for each grandparent. Tag each Match in these Clusters to the appropriate Ancestor (grandparent). Then adjust the threshold to get (roughly) 8 Clusters (one for each Great grandparent). These Clusters would include all the Tagged Matches who would indicate which grandparent line each new Cluster was in; as well as new, generally more distant Matches, who would then separate these Clusters into Great grandparents. Tag, or re-Tag, each Match in these Clusters to the appropriate Ancestor (Great Grandparent). Then lower the threshold to get 16 Clusters and repeat the process.
Up Front DISCLAIMER: This is not a simple click-and-done process. There is homework to be done before Clustering: documenting the Common Ancestors in our Matches’ Notes. Although the time it takes to run various Cluster reports is only a few seconds for each one, it takes some time to analyze the Matches in each Cluster and come to a consensus, then transfer those clues to the next Cluster, and then analyze those Clusters. It turns out this WTCB process is iterative –two steps forward, then one back. Each new set of Clusters brings in new Matches with clues that need to be reconciled. WTCB is somewhat easier than Triangulating all your Matches, but it is still time-consuming work. Nevertheless, WTCB is a great opportunity to get the most out of your Matches at AncestryDNA.
Background
Clustering is a way of grouping your Matches. Each Cluster tends to group Matches who descend from the same Ancestor. The Leeds Method groups close-cousin Matches into four Clusters which are usually our four grandparents. On the one hand this depends on knowing the Common Ancestor with some of the Matches; and on the other hand it provides a strong clue about the Ancestor of other Matches in a known Cluster. And if some Clusters are known, the others may be determined by logic. Clustering provides a powerful grouping tool. I posted about Grouping Matches here; and about several Clustering programs here.
The Leeds Method uses a high threshold (90-400cM) for the Matches to be included in the analysis, so that only 2nd or 3rd cousins are used. Each cousin in this range would usually be from only one of our four grandparents. What would happen if we lowered the threshold just enough to only have 3rd or 4th cousins most of the time? Generally they would tend to form eight Clusters – one for each of our eight great grandparents. However, as with most things “DNA”, as we decrease the cM threshold, we get a wider range of relationships – it’s not very probable that we could find a cM threshold that would produce exactly eight Clusters, or even succeeding in that, that there would be a 1-to-1 relationship to our eight Great grandparents.
And if we decided to jump to the ultimate and Cluster on 6cM, I can tell you that we’d get hundreds of Clusters. Some of them we might be able to identify, but most will look like “mush”. And, like finding a DNA Match who is a 9th cousin, we wouldn’t really have much in the way of corroborating evidence.
However, we often do have a lot of data to work with, and a good tool like Clustering that makes it fairly simple to group our Matches…
It struck me that maybe we could Walk The Clusters Back (WTCB). See the concept in the Executive Summary. In theory the 8 Clusters would be husband/wife pairs – the parents of the grandparents in the original 4 Clusters. The 4-Cluster Matches would carry a “tell-tale” Tag of whence they came to the 8 new Clusters. Then, hopefully, with clues from the new Matches in the 8 Clusters, we could determine which of the great grandparents each of the 8 Clusters represented. We are down to only two options for each Cluster, and if we can figure out one, the other would determined by logic: i.e. the other parent.
In general this worked! But it didn’t always work per the theory (the DNA is random), and the process was arduous.
Problems
– Even by adjusting the Cluster threshold 1cM at a time, the Clusters rarely came out to 8, or 16, or 32, or 64, or 128. And even when it came close, all of the new Clusters were not necessarily just the parents of the previous Clusters. Sometimes one Cluster would split into 3 or 4 Clusters (a parent and 2 grandparents, or 4 grandparents). And from one iteration to the next, some Clusters didn’t split at all. As the threshold dropped and the number of Clusters increase, the deviation from the theory increased. Not wholesale, not all of them – but enough to notice.
– In my case (one grandparent who had very few Matches, and thus very few Clusters), I knew I would get only 2 Clusters max for that one grandparent. If you have a special case, you need to make some adjustments (I used 4-8-13-26-50-98 as my target Cluster numbers and took whatever was closest).
– Sometimes in a Cluster, I didn’t get any/many Matches who had a CA. Each new Cluster depends on Matches with CAs to inform us about the probable CA for the Cluster. I could usually make up for this in the next iteration, but that meant I had to backtrack – which I did more and more as the number of Clusters increased.
– I had to find a way to transfer the Ancestor tell-tale Tags from Matches in one set of Clusters to the Matches in the next Cluster run. More on this later.
Developing the process

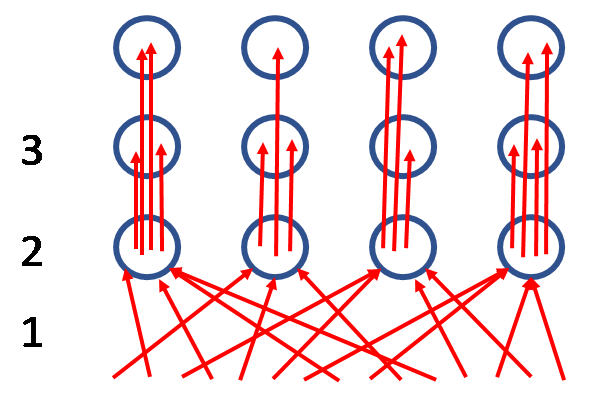
In step 1 of the above figure, all the Matches above a 90cM threshold are Clustered into 4 groups – one for each grandparent. In step 2, based on the known genealogy of some of the Matches, I determined the 4 grandparent Ancestors based on information I know about the close Matches in each Cluster. In step 3 I adjusted the threshold to create about 8 Clusters, and noted which of the Matches from steps 1 and 2 are now in the new Clusters. Generally the Matches from each of the 4 Ancestors (grandparents) in step 2 will be found in only 2 Clusters at the step 3 level. There are only two options for these two Great grandparents, the husband and the wife of the Ancestor in step 2. Often at this point, we don’t always know which is the husband and which is the wife, but we can be confident it’s one of each. However, during step 3 we also get additional Matches (not shown) in the Great grandparent Clusters. Some of these new Matches may be 4th cousins who would provide insights on the identity of the Great grandparents. The other Great grandparents will become known after step 4 as shown below.

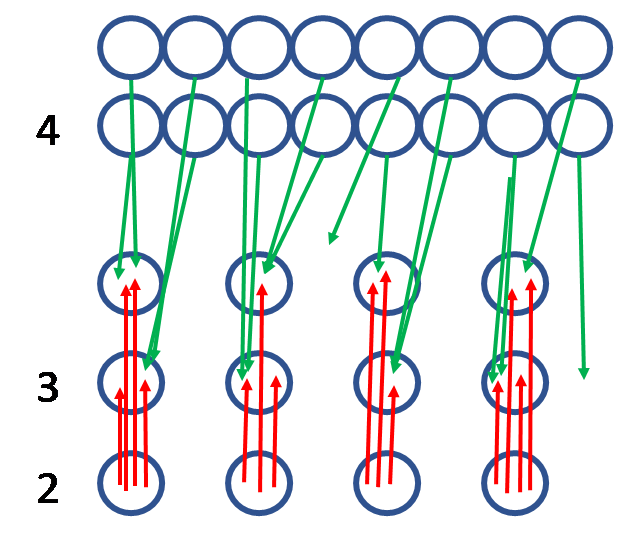
In step 4 above, we lower the threshold again and get roughly 16 Clusters. I’m just using a single green arrow to show all the new Matches who were 4th, 5th and 6th cousins who formed the 16 Clusters (along with the closer red arrow Matches from steps 2 and 3). At this point, all we’d need is the CA of some of the more distant Matches, in order to determine the correct Ancestors at level 3. Note that two of the green arrows don’t point to one of the 8 level 3 Ancestors – don’t worry about it. These “errant” Matches will often fall into Clusters in the next iteration. Or maybe they will continue to be strange. Again, don’t worry about it – focus on the Ancestors you can determine. Some of the data will get a little messy as the threshold is dropped. Focus on the positive outcomes – the identity of the Cluster Ancestors at each generation.
Step 4 above shows that this is an iterative process: we sometimes need the CA couple information from one generation to resolve the individual CA of a closer generation. Note that this changes the Tags, which needs to be reconciled in a prior generation Cluster.
The Iterative WTCB Process
This led me to modify the theoretical process at the beginning of this post to the following iterative, or zig-zag, process.

- Set the threshold to get 4 Clusters; Assign each Cluster to a grandparent Ancestor; Tag each Match in 4-Cluster with the appropriate Ancestor.
- Reduce threshold to get 8 Clusters [with Tagged 4-Cluster Matches plus additional new Matches (some with CAs in Notes)]; as best you can, assign Clusters to Great grandparents; Tag all Matches with what you know so far.
- Re-run 4-Clusters, to insure the new Tags are OK, adjust as necessary.
- Re-run 8-Clusters, and adjust as necessary.
- Reduce threshold to get 16 Clusters [with previously tagged Matches plus additional new Matches (some with CAs in Notes)]; as best you can assign Clusters to 2xG grandparents; Tag all Matches.
- Re-run 8-Clusters; usually some new Tags will clarify any Great grandparents that were unclear in Step 2. Re-Tag as appropriate.
- Re-run 16-Clusters and adjust as necessary.
- Repeat steps 5, 6 and 7 (adjusted to for the next round): Reduce threshold/assign/Tag; revisit the prior Clusters/Re-Tag as appropriate; re-run the current Clusters/adjust as necessary.
This 2-steps forward then 1-step back process is necessary because it’s not always clear when one Cluster splits into two new Clusters which is the father and which is the mother – this usually becomes clear in the next round which includes more distant cousins. If something doesn’t work out in one round, it will probably get resolved in a subsequent round. Until, of course, you run out of sufficient data. Theoretically, each of your Ancestors with ThruLines Matches will be incorporated into a Cluster. Generally that would result in a lot of known Clusters. And if some of your Matches uploaded to GEDmatch or tested at one of the other companies, you’d also have TG information included in the Clusters. Happy days of DNA Painting or Chromosome Mapping!
Some Additional Items
Homework before WTCB
Create Notes in AncestryDNA for as many of your Matches as you can (hopefully you’ve been doing this all along). See my previous blog posts about AncestryDNA Notes: Format; Using Notes; ID for CAs; ID for TGs. These Notes are then handy and invaluable in the WTCB process – they provide the clues that let you determine a consensus in a Cluster. They remind you of the CA and TG information you’ve already gathered.
Work with generations
It would be possible to start with a large cM threshold to get 4 grandparent Clusters, and Tag the Matches. Then decrease the threshold by 1cM and run a new Cluster report. Has any new Cluster been added? If no, then decrease the threshold by another 1cM and repeat. If yes, it’s probably the result of a split of a previous Cluster into two parents. Identify the parents, and Tag the Matches appropriately. Then decrease the Cluster threshold by 1cM and repeat. This would take a lot of work.
The process I choose was to lower the Cluster threshold by enough to create roughly twice the number of Clusters. This would basically be creating the next generation of Ancestors. The random DNA doesn’t allow this to work perfectly, but it does tend to subdivide previous Clusters into new Clusters. Focus on identifying (through Tagged Matches) which Clusters came from previous Clusters; and then identifying the next generation of Ancestors in these new Clusters. Again, this doesn’t work perfectly each time. But don’t worry about it, a subsequent set of Clusters (with new Matches and new information), will usually provide resolution (through the iterative process – see below).
Tagging Matches
The key is to Tag Matches and carry over this information to the next set of Clusters. Now in this new set of Clusters you have Matches with information carried forward, plus new Matches, some of which have known information of their own (available in the Notes). Again, your focus is to achieve consensus in each new Cluster, and re-Tag the Matches..
I use the Ahnentafel number as the Tag. Other options include: Ancestor name, Ancestor initials, or Ms and Ps (e.g. MP for maternal grandfather). The Cluster number changes with each different iteration, so don’t use that.
One way would be to add the Tag into the Shared Clustering spreadsheet Note field for each Match; then use the Shared Clustering program to upload the Notes back to AncestryDNA and also to the Download file (where it would be available for the next Cluster run – remember the Cluster runs on the Download file only take a few seconds).
I choose to use the Shared Clustering spreadsheets (after stripping out the colorful Clusters – keeping just the data). I combine two Cluster files, sort on Match name, and copy the Tag from one Match to the other. This is relatively easy for small Clusters, it gets more time consuming with each iteration.
An iterative process
WTCB is definitely an iterative process. When we add new generations of Clusters and find new Matches with clues, we need to then backtrack to previous Cluster runs with this new information. Why backtrack? Because with each succeeding generation of Clusters we are (roughly) adding two “parent” Clusters for each one we had before. Sometimes we don’t have enough information to distinguish which of these two “parent” Clusters are the father or the mother. But in the next Cluster iteration, we find new information among the new Matches who are added in each round. When we backtrack with that information, and designate one of the two “parent” Clusters as, say, the mother, then we can impute the other one to the father – and then further Tagging all the Matches in those two Clusters, and all subsequent Cluster runs.
All the Clustered Matches are valuable
At first I intended to cull out the Matches for which I had no Notes – they didn’t appear to add any value. They didn’t reveal a TrueLines CA or a TG or anything else – nada. But then I realized they did add value – they were part of the heat in the heatmap. They added the value of being assigned to a Cluster (because of their Shared Matches), notwithstanding the fact that I didn’t know anything specific about them. In the next iteration of Clustering (with a lower cM threshold) they would also be included. If I Tagged them per the current Cluster, this information would carry over to the new Clusters. In theory (and borne out in practice), they tended to divide between two Clusters in the next iteration. Of course they couldn’t help me figure out the CA of those two clusters, but the fact that they helped form the Clusters gave weight to the new Clusters. Sometimes they were the Matches needed to actually form a new Cluster, and without them I wouldn’t get that Cluster. And their Tag told me I had only two possibilities for these new Clusters – the two parents of the Tag. And in these new Clusters there were new Matches – sometimes ones who were ThruLines Matches with a CA, or a Match (with no genealogy) who had uploaded to GEDmatch, and thus had a known TG. And sometimes I got nothing from these new Matches, but then did find new clues in the next generation of Clusters.
The value of Common Ancestors with low cM shares
Some of my Matches with CAs (from ThruLines out to 6C or Circles out to 8C) have smaller shared segment cMs – all the way down to 6cM. I treat these as clues – they can be helpful in developing a consensus with other evidence. With this WTCB process, we only have two Ancestor options at each generation, so even a 6cM Match may be a valuable clue.
Two kinds of Imputation possible
– Cluster Imputation: When one of two “Parent” Clusters can be determined (usually by a Match who has a known CA); the other “Parent” Cluster can be imputed to be the other Parent. Then all of the Matches in both “Parent” Clusters can have their Tags adjusted appropriately.
– Match CA Imputation: Cluster CAs (or the ancestral line) can be imputed to all the Matches in a Cluster. On many occasions, with Clusters with a strong Match consensus for a CA, I’ve gone to other Matches in the Cluster looking for that CA and found it.
How Far Can We Go?
Continue this out as far as you want? Well, it’s not quite that easy. There are several things at play here:
- As noted above, the lower the cM threshold used, the wider the range of relationships we’ll get. As the threshold drops, we’ll see a wider range of Ancestors for each Cluster.
- Some of our Match-cousins share multiple relationships with us. Just look at your ThruLines Matches to see the number of them who share more than one ancestral couple with you. At a 20cM threshold, 65 of my 296 Matches (22%) share more than one pair of Common Ancestors with me.
- Some of our Match-cousins share multiple DNA segments with us. This means those Matches could share multiple Ancestors with us. Which one should we use? At a 20cM threshold, 1744 of my 4506 Matches (almost 40%) share more than one DNA segment with me.
- However, if a Cluster with Matches at one level, splits into two Clusters, each with some of those same Matches at the next level, it’s fairly safe to use that information as a strong clue (or hypothesis).
- We now have ThruLines at AncestryDNA. I have over 1,800 Matches in my ThruLines, and they “cover” all of my known Ancestors out to my 5xG grandparents (6th cousin level). Those that wind up in Clusters, provide valuable clues about the Ancestor for those Clusters. Couple that with the Matches with “Tags” from previous Clusters, and you have reinforcing (or conflicting) clues.
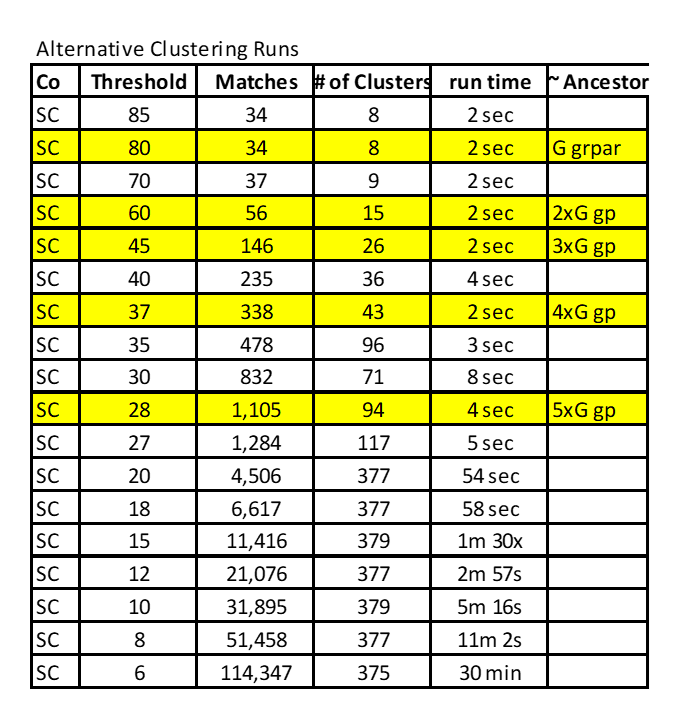
Here is a Table of my Cluster iterations – I used the highlighted ones in this study.

SC = Shared Clustering program by Jonathan Brecher (used for this WTCB analysis)
Concluclusions:
- It is possible to Walk The Clusters Back. I think the trickiest part is assigning Tags to Matches that stay with the Match in succeeding Cluster runs. I plan to try using the Shared Clustering Upload program for that (upload to Ancestry and the Download file)
- WTCB is not a simple “click” process – it involves homework (CAs in AncestryDNA Notes), and judgment, logic and time working with the Cluster iterations.
- It gets harder (both in logic and the number of Clusters and Matches involved) with each iteration.
- Some of my Matches have uploaded to GEDmatch or tested elsewhere and I have TGs for them. WTCB will provide a strong clue for the CA of these TGs.
- I think the realistic limit will be around 7xG grandparents (8th cousin level).
- WTCB helps us impute CAs to Matches.
[19D] Segment-ology: Walking The Clusters Back by Jim Bartlett (20191201)