This is my ultimate spreadsheet, so far. I think it’s use will be profound.
The spreadsheet and data are pretty simple. Here are the header titles:
Side – Paternal or Maternal [I use Ahnentafel number 2 or 3]
Chr – Chromosome number (1 to 23)
Start – the Start location of each Triangulated Group (TG) use Mbp with one decimal
End – the end location of each TG (Mbp) NB: End of one TG = Start of next TG
Mbp – calculate End minus Start; this is “roughly” the cM (real cM is too hard to calculate)
TG-ID – An ID for each TG – Example 01S2 – on Chr 01, Start ~130Mbp, on 2 side
For more see: Shorthand ID for TGs
G2 – second generation back, column for Ahentafel number for my Ancestor
G3 – Ahnentafel for one of my grandparents; similar for other generations below
G4 –
G5 –
G6 –
G7 –
G8 –
G9 –
G10 –
CZN – Cousinship of Most Distant Common Ancestor (MDCA) in this TG [within reason]
MDCA – the surnames of the MDCA Couple Ex: SNIDER/BRITZ
Remarks – a place for any discussion I want about a TG – I could write a book in this cell.
For the spreadsheet header, just type in the above list (to the left of the hyphen) across the top row.
This simple spreadsheet has two parts:
1. Side|Chr|Start|End|Mbp|TG-ID – this describes each TG. I have 372 TGs so my TG Summary Spreadsheet has 372 rows of data. Having already done segment Triangulation of all my Matches at FTDNA, 23andMe, MyHeritage and GEDmatch, this part of the TG summary was a snap. And these data points remain fairly static. I say “fairly” as from time to time, as new Shared DNA Segments are found and new MRCAs determined, I do make minor TG end-point shifts and/or combine or split existing TGs.
2. G2-G10|CZN|MDCA – this part summarizes the genealogy – the Most Recent Common Ancestors (MRCAs) I have with Matches in the TG; and my best, conservative, judgment of what is the MDCA for the whole TG, so far. For each of the reasonable MRCAs in this line I enter the Ahnentafel number of the MRCA – bolded and yellow-highlighted – under the appropriate Generation. See the Figures below. This represents the data that I’m comfortable with. The goal is to Walk the Ancestor Back in each TG, and/or to find multiple, separate Matches who agree with the Ancestral line. In some cases, where I have sufficient evidence, I underline the Ahnentafel numbers to indicate I’m confident with the result. In the other cases the Ahnentafel numbers are clues, and more data is needed. In some TGs I have no MRCA, yet. In just a few TGs (less than 10), there are no Match-segments (beyond very close relatives) – these are small gaps in the overall Chromosome Map.
Both of the two parts above come from my atDNA Master Spreadsheet which has all my Shared DNA Segments with Matches. That spreadsheet is now over 20,000 rows – this TG Summary spreadsheet is 372 rows which I can print out in two pages back to back. A very handy scrap of paper.
This is the spreadsheet version of DNA Painter. In fact I once painted the 372 TGs. And I did the same with Kitty Cooper’s Chromosome Painter program.
Several observations about this TG Summary Spreadsheet:
1. It is a summary! It extracts the important essence from 20,000 rows of data into 372 rows.
2. Trends – By bolding and highlighting my Ahnentafel numbers I can readily see trends and/or conflicts.
3. Pointers – For TGs with strong evidence of an MRCA, this information is very valuable in looking at other Match Trees in the TG. *Knowing* the TG MRCA is a powerful pointer, which has helped me find MRCAs with many more Matches (including those with only one Ancestor in their “Tree”). This summary has become a powerful TOOL in this respect.
4. Fill-in – In many cases, based on high confidence MRCA Ahnentafels, it is easy to “fill in” the other Ahnentafel numbers leading up to the TG MRCA – these “fill ins” identify the Ancestors who “had to be there” for the DNA to pass down to me.
5. Crossover points – With “filled in” Ahnentafels, it’s easy to see where the crossovers occurred between TGs in a Chromosome. If one TG row has Ahnentafels 2-5-10-21-42 and the next row has 2-5-10-20-40, it’s easy to see the crossover occurred between 21 and 20. In this case, Ancestor 10 had these two adjacent TGs in their DNA – one from his mother (21) and one from his father (20), which he (10) recombined and passed as a single, larger TG segment to his daughter 5. A first cousin (1C) might share that larger segment with me. And, of course, parent 2, would have also passed that *double* segment to me intact as part of that Chromosome. In other words, as we fill out the MRCA Ahnentafels, we can track the crossover points, generation by generation.
6. Crossover points per generation – This also gives us the ability to easily count the crossovers per generation. Will we see the 27 male vs 41 female distribution? On the paternal side we can see how many times the TGs shifted from 4 to 5 (or 5 to 4) [no matter what distant MRCA each of those TGs eventually went to after that]. How many 8 to 9 and 10 to 11 cross overs will there be – will it stay near 27 or tread toward the 34 average?
7. Quality Control – The Crossover points per generation summary may be a good QC check – if our result from the TG Summary Spreadsheet is reasonable. If my TG summary shows a lot of change between TGs, I might show 50 or 60 crossovers in a generation – that seems unreasonable to me, and I would be looking over my TGs. It would be relatively unusual for a Chromosome to shift from one grandparent to another and then back again several times on one Chromosome – it’s more likely that I had several MRCAs in a TG and selected the wrong one.
8. Predictive – I have some TGs with no or a very close (2C) MRCA. In some cases, it’s where much of the Chromosome is from one grandparent. If one TG in the middle is from the other grandparent, that adds two crossovers to the total. Although I’m pulled toward the parsimonious solution, I have to ALWAYS keep from jumping to a conclusion. On the other hand, if my total crossovers for the generation is high, I need to look hard for errors I might have made.
9. Brick Walls – In some TGs I have several Matches at, say, the 4C level, and a lot of other Matches, some with good Trees, but no MRCA beyond 4C level. All other things being equal, I should have some 5C and 6C Matches in that TG (I have ThruLines Matches at Ancestrycom for all of my known 6C Ancestors, so I know the genealogy is there if the TG was really from one of them). So I conclude that those TGs are probably headed past the 4C level and on through a Brick Wall. I’ve used this conclusion to successfully use Match Trees to find a Common Ancestor in two TGs with Brick Walls; and in one case where I had an incorrect Ancestor. Where there are a lot of Matches in a TG with closer Cousins, I am suspicious of an Ancestor I haven’t identified. Alternatively, I also have some TGs with no close Matches and lots of distant apparent Matches – sort of like a pile up area. This situation leads me to believe the MRCA may be at the fringes of my genealogy or beyond. Maybe adjacent TGs will be able to help…
10. Chromosome Maps/Generation. As I’ve mentioned in several blog posts before – each parent gives us 23 chromosomes and all 3 billion base pairs in a genome. On each side, our two grandparents provided segments that account for the same 3 billion base pairs – through roughly 57 segments that cover all of our Chromosomes. And so it goes for each generation – our Ancestors in each generation provide sufficient segments to fill up all our Chromosomes. With this TG Summary spreadsheet, it’s easy to see the segments from any Ancestor in a generation. For instance my father’s mother’s Ahnentafel is 5 – I can look down column G3 and see which TGs have a 5 and easily note the appropriate Start and End points to get the Mbp for each grandparent segment (or I could resort the spreadsheet on column G3 and just sum the 5s). Repeat for Ahnentafel 4 – the sum of Mbp for 4 plus 5, had better add up to the whole for that side. [arithmetic check!] I could Paint or map those segments which would cover all of my Chromosomes. Do the same thing with Ahnentafels 12 through 15 on my maternal side to map (or Paint) my great grandparent segments. It all depends on how much of the TG summary I can fill out.
11. Sticky Segments – It’s easy to see “Sticky” segments – a segment of DNA that must have traveled down many generations intact to get to me. See TG 09A24 in Figure 3 below. Yes, this segment probably started out somewhat larger, but the segment I have in my body (TG 09A24) had to persist from Ancestor 354, through 8 generations, to me.
12. Progress – This TG Summary spreadsheet offers a good way to track your progress (if your objectives include linking Ancestors to Segments, or “proving” your Tree with DNA).
13. Focus – In any case, this TG Summary spreadsheet helps me focus on the *Most Distant Common Ancestor* Chromosome Map objective.
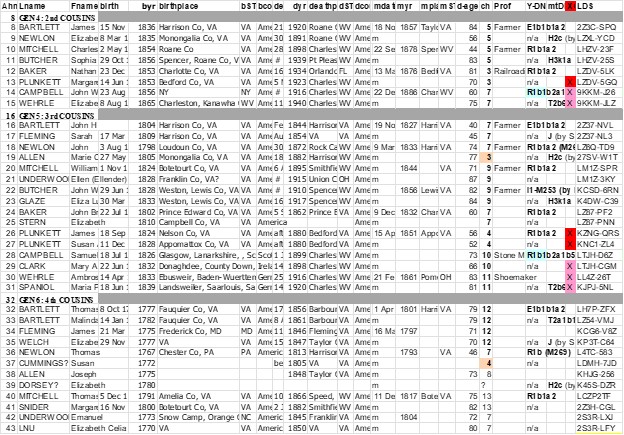
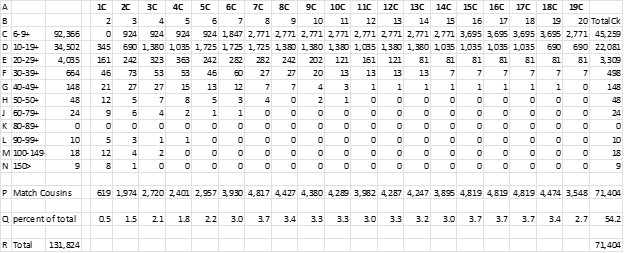
Here is part of my TG Summary Spreadsheet only with known MRCAs (bolded & highlighted) Ahnental numbers :
Figure 1
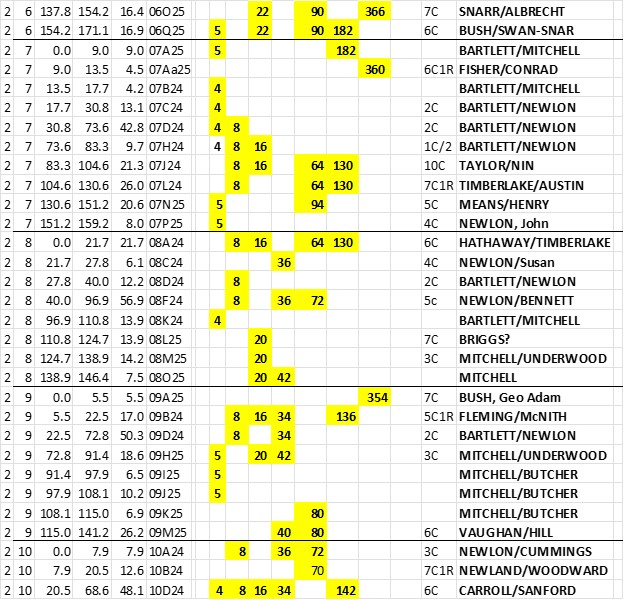
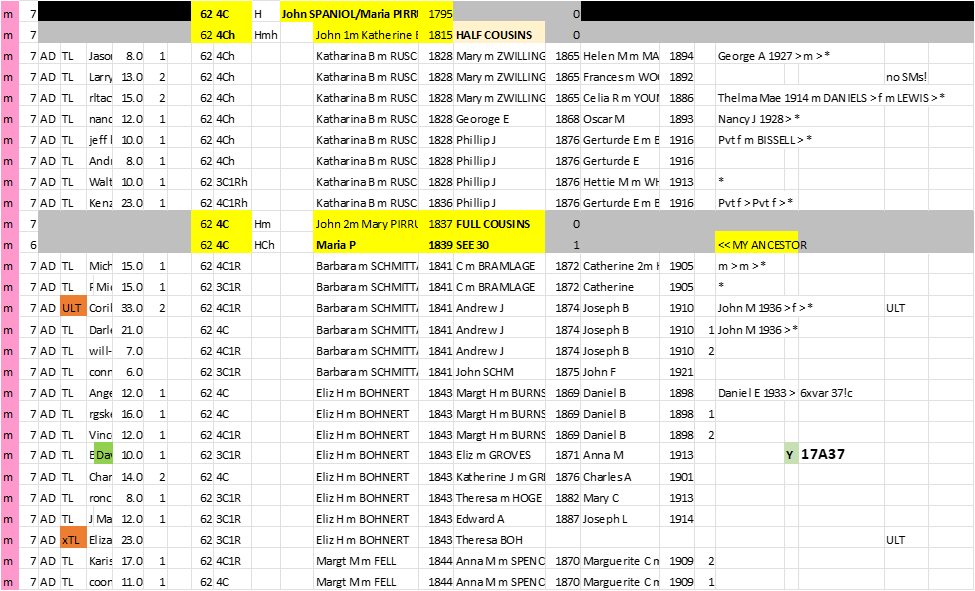
Next is part of my TG Summary Spreadsheet including “must be” Ancestors. And a few of the known, even numbered (husband) Ahnentafels were changed to odd (wife) Ahnentafels – as appropriate.
Figure 2.
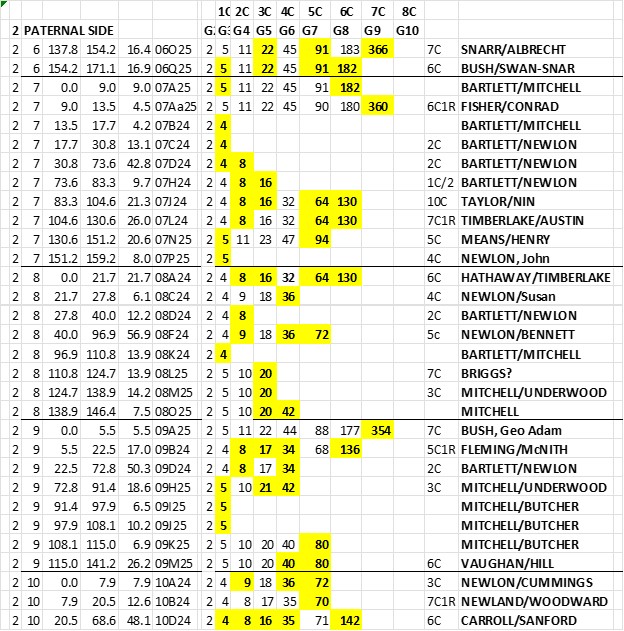
Now, below, I’ve added some double underlines at crossover points:
Figure 3.
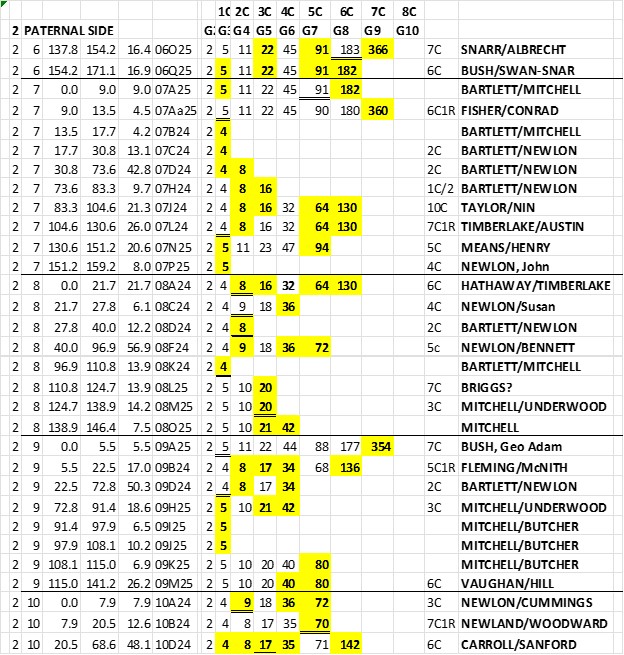
NOTES on this Figure 3:
1. Note the 183 to 182 crossover between TG 06O25 and 06Q25. Ancestor 91 had the two segments as maternal and paternal segments and passed them on as a full maternal segment to Ancestor 45, which then must have been a “sticky segment” down to me.
2. Note TGs 08A24 through 08F24 appear to flip-flop from 8 to 9 to 8 to 9. That almost certainly would not happen. And upon examination I see that TG 08D24 should have been changed from 8 to 9 [NB: by convention I use an even Ahnentafel to represent an MRCA couple, which is this case would have been 8 & 9– so the 08D24 8 has an equal chance to be a 9. Given that both adjacent TGs are a 9, the best guess is to make it a 9. Then there is 1 crossover instead of 3.
3. While we are looking at Chromosome 8, it looks like the 9 will crossover to a 10 before 08L25 starts; but the crossover will actually be in G3, and TG ID 08K24 could be either a 4 or a 5 in G3. This would mean one crossover in Chr 8 in Gen 3 – highly probable for Chr 8.
4. Look at TG 09A25 – two things: although it’s 5.5Mbp long, don’t be fooled – most of the Shared DNA Segments in 09A25 are 15cM segments; and only one Match has a distant MRCA at Ahnentafel 354 – this is a fairly iffy, and I would not be surprised if someday I found a closer paternal cousin on this segment – even one on a 2-4 branch (but for now this is the only clue I have for this TG, and I’ll keep it until something better comes along).
5. Look at TGs 07L24 and 07N25 – there is a crossover here at G3, and the two TGs go back in two very different directions (to two very different geographic areas). I generally find that this type of crossover is fairly crisp, and easy to identify. Other TGs with crossovers somewhat more distant seem to have a fuzzy overlap – often the crossover point cannot be readily pinned down. I such cases I just pick a compromise crossover point. As I’ve noted before, our focus should be on the bulk of the TG segment, from an Ancestor, and not be too concerned about a little fuzzy overlap of TGs.
SUMMARY THOUGHTS
REMEMBER: Your Ancestry is a very unique arrangement of Ancestors – which does not change. Your DNA is a unique tapestry of segments and crossover points – which does not change. Your DNA is linked to your Ancestors in one way – which does not change.
All of our tools help us to determine our Ancestors and segments and how they are interconnected. The Leeds method and Virtual Phasing can help with Generation 3 (G3 above) – the results should be the same as your grandparents and your grandparent segments. DNA Painter can help paint the same segments you see in the TG SUMMARY above – but more colorfully, and perhaps closer to your style of figuring things out. Clustering (in all its various manifestations); Shared Matches (aka In Common With; Relatives in Common, Shared DNA Matches); segment Triangulation (by GEDmatch, MyHeritage, 23andMe, or DoubleMatch Triangulation at FTDNA; or through a Spreadsheet, as I do); and Trees and genealogy Tools primarily at Ancestry – are all good tools that are designed to help find Common Ancestor and DNA segments. Use the tools that work best for you. This TG SUMMARY may also help you.
SUMMARY – NB: This spreadsheet summarizes WORK. It summarizes the segment Triangulation of many DNA Matches – not an easy task, but one when accomplished, remains relatively static. It also summarizes a lot of genealogy WORK determining Common Ancestors with our Matches. As we document our TGs and dig into the genealogy, we begin to build a mountain of evidence linking our Ancestors to our DNA, and vice versa.
[35BE] Segment-ology: TG Summary Spreadsheet by Jim Bartlett 20211222