Using a 20cM threshold at AncestryDNA, I got 156 Clusters. That’s roughly one Cluster for each of my 128 5xG grandparents – or two Clusters per 5xG grandparent couples – often with valuable Common Ancestor (CA) hints from ThruLines. I don’t know 50 of my 128 5xG grandparents (they are brick walled) – so I would expect (50×156/128=) 61 of my 156 clusters to be blank. What’s a body to do?
Well… in the first place the above calculation is based on finding a CA at the 5xG grandparent level. ThruLines provides clues for all the Ancestors I know – but, clearly, they cannot help with Clusters (or TGs) beyond a brick wall. For almost all of the Clusters, I know the parent; and for roughly 80% I know the grandparent; and for many I know the CA out to the brick wall. So I’ve got a start. But, for many of my Clusters, there is very little otherwise to go on – just a lot of Matches in a Cluster. What’s a body to do?
As I’ve said before, let’s think about lemonade… In my last post (Using a Group Ancestor), I noted that grouping (segment Triangulation and Shared Match Clustering) results in a group of Matches with the same Common Ancestor (CA). This is the concept, even if we don’t have any clue as to who the CA is. But let’s make “the certainty that there is a CA” work for us… Let’s have the Matches tell us who the CA is for a Cluster. Seems like lemonade to me.
Here is a process for AncestryDNA: [I hope you’ve saved your last Cluster report]
- Select a large Cluster for which you have no known CAs (or only a few which are in conflict with each other).
- Make a spreadsheet with three columns: Match Name and Surnames and Notes.
- Select a Match in the Cluster who has a Tree with more than 99 people.
- Type the Match name in the spreadsheet.
- Go to that Match in AncestryDNA (either from the URL in the Cluster; or by searching AncestryDNA).
- Type the surnames for that Match (both Shared Surnames & Match’s Tree Only) in Surname column.
- Copy the Match name down the spreadsheet for each surname.
- Repeat for each Match in the Cluster with a Tree over 99 people.
- Sort the spreadsheet on the Surname column.
- Scroll down the list and highlight likely Surname groups [it would be great to find a clear winner – repeated multiple times. If not pick the top few surnames].
- Go back to the Matches with most likely surname(s) and put in the Notes column the Patriarch or any other identifying information (birth, location, ethnicity, etc). The expectation (hope) is that you’ll find a Common Ancestor or two in this process.
I can almost hear the collective groan at step #6. Yes, it’s an onerous task. I sat down with a favorite beverage and typed non-stop the 660 surnames for Matches in one Cluster; 750 in another Cluster. But, think about this another way: would you spend a half-day of work to find a new Ancestor? That would be a nice glass of lemonade.
In my first Cluster try, I found three Surnames (ADAMS, CAUDILL and CRAFT) repeated several times. A quick and dirty Tree quickly determined John ADAMS married 1769 Loudoun Co, VA Nancy CAUDILL; and their daughter, Elizabeth married Archelous CRAFT – and 5 of my Matches in the Cluster descended from these two couples!! I already had some clues that this Cluster was on my father’s father’s side. This includes my NEWLON line which had a brick wall born c1774 Loudon Co, VA which I determined was Susan CUMMINGS – blogpost here. Her father is strongly suspected to be John CUMMINGS born c1746, but nothing is known about John’s first wife, the mother of Susan CUMMINGS and my Ancestor – a new brick wall. If John’s first wife was an ADAMS, all of this would fall into place as a hypothesis.
By the nature of Shared Match Clustering, this Cluster must have a CA. With five widely separated Matches agreeing on the same CA (and no other surnames turning out any hints at all), I think this is a strong clue. But, more research is needed.
The other Cluster had several repeated surnames, but none that I have been able to link together, yet. I may drop down and look at the surnames of Matches with Trees in the 50-99 people range… maybe another hour of typing… If I find a clue it will all be worth while.
Bottom Line: A Cluster (or a TG) has a CA. The Matches in a Cluster should all share this CA. Let the Matches Tell Us the Cluster Common Ancestor. The process above is one way to do this. A particular advantage to me is that this process is comprehensive, and with no bias – the data from the Matches is treated evenly.
Post Script: By it’s nature genealogy is an ego-centric hobby. We tend to focus on ourselves as the center of the universe. Or, if we are professionals, we treat the Client as the center of the universe. Everything revolves around our Ancestors and what we can find out about them. But each of us is a small part of the human race, and our Matches – our cousins – are part of this larger picture. They fit in, too. They are an interlocking part of the whole jigsaw puzzle, and in some (many?) cases, some of them know more than I do . The process above draws on the data they have provided. Often, they have clues to the solutions we seek. Often, they know what’s on the other side of our brick walls.
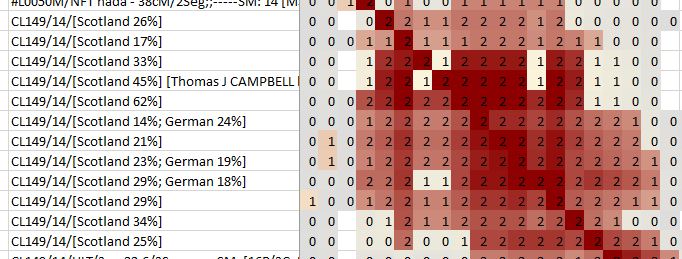
Edit 6/22/20: I’ve been asked to add a photo of my spreadsheet. Here it is – showing the top two surnames.

The 3rd column is Match Names and it has been narrowed for Match privacy. When I started, I had columns for Company and Where (the name of the Cluster run – 20cMCL63: Cluster 63 of the Shared Match run using a 20cM threshold), but it turns out this is a Quick and Dirty spreadsheet, and I didn’t need those columns. The objective is to get started on a Quick and Dirty Tree, and work from there. As soon as I saw the last line – a CRAFT married to an ADAMS, I started the Q&D Tree and found the five Matches who all tied together. Since then, I’ve used the previous blogpost on Searching and have found over a dozen more Matches who descend from this same line. All of the Cluster Matches were over 20cM. However, now knowing what I’m looking for, the Search process let me drop below 20cM and find many more – and most of them have above-20cM Shared Matches from the same Cluster. This is added evidence that I tie into this line some how.
[19H] Segment-ology: Let the Matches Tell Us the Cluster Common Ancestor by Jim Bartlett 20200620