A Segment-ology TIDBIT
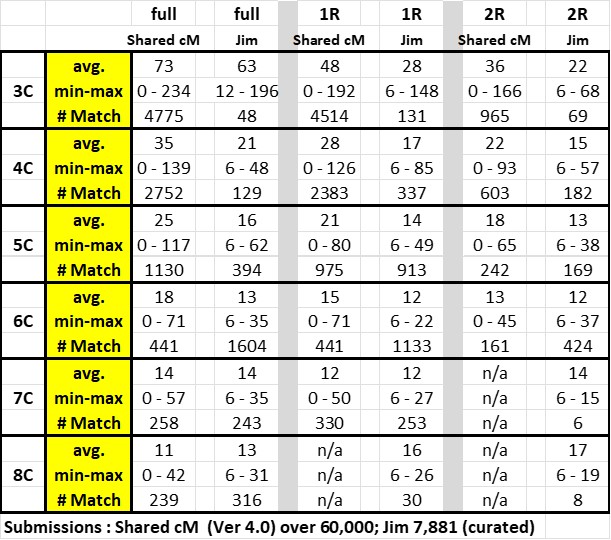
Ancestry ProTools includes several features. ProTools costs $10/month extra on an existing Ancestry account. This post is focused on the cMs between Shared Matches. I’ve fiddled with it for a few days, and, of course, have come up with a helpful spreadsheet.
One method: Focus on a “base” Match of interest to you.
Start with a Match of interest to you (often a high-cM Match with an unknown, or iffy, link to your Tree). I call this the “base” Match. Click on Shared Matches (to use ProTools or subscribe to it).
The resulting Shared Match list (with ProTools) took me a while to get used to. It is essentially a list of the Matches that you and your selected Match have in common. This is a fundamental building block of Shared Match Clustering, and Matches who appear on each other’s Shared Match lists tend to all have the same Common Ancestor. These Clusters can include Matches with Trees (where you can search for a Common Ancestor among them); as well as Matches with Unlinked Trees, Private Trees and NO Trees)
However, the ProTools Shared Match list also reveals the cMs shared between your “base” Match and each of the Shared Matches on the list. These cMs may, or may not, be significant information. So far, the list is only arranged by cMs shared between you and the Matches. I’ve found my “go to” process is to scroll down the right hand list and check the cMs shared between your “base” Match and each of the Shared Matches. This is often a wide range of cM values – from 20cM up to some real surprises. These surprises may be on the last page of Shared Matches – so, for me, it’s well worth the time to look at all the pages of Shared Matches (20 Matches per page). There is a rumor that Ancestry is working on way to let us sort on this value. I have found several cases of a relatively small Match to me, who is a parent, or child, or sibling, or other very close relationship to the “base” Match. This is often a “BINGO” for me – particularly when one or the other of this duo doesn’t have a Tree. These close relationships can also be game changers – 1C, 2C or even 3C can show a family group in one “sub-branch” of your Tree – importantly, separated from other branches.
Inverse Logic: If you are pretty sure of some Matches who descend from one child of a particular Ancestor, and a group of Matches (among themselves), appear to be on the same line, but their cMs with you are somewhat smaller than the other Matches from that Ancestor, then this is a strong clue they are related another generation back, or so.
In any case, this info can be very valuable in conjunction with a WATO analysis at DNAPainter.
Another method: Work on your top Matches on one branch of your Tree.
Of course I tried several spreadsheet methods. The one that works best for me is a list of my top Matches on one branch of my Tree. I determine these Matches from my Notes (derived from ThruLines; Clusters; UnListed Trees; blind luck; etc). Almost all are captured in my Common Ancestor Spreadsheet – here). Since I know how most of my Matches relate at the grandparent level, I focused on the Great Grandparent groups and/or 2xG Grandparents who were on my paternal side. In other words, on known, or suspected, Ahnentafels: 8P, or 16P and 18P, or occasionally one more generation back (32p-39P).
I walked down my Paternal List of Matches and selected the ones I had Notes for that indicated they were from my targeted branch, or, based on previous Clustering, who were Likely to be on that targeted branch (Likely Matches were labeled with an “L”, and usually had NO or very small Trees.) I listed the Match Name, cM, Relationship (e.g. 8P/2C1R), and sometimes the Child the Match descended from. Feel free to add any columns that might be helpful to your analysis – columns can always be moved or deleted or hidden. Out of this list I selected a Key Match (often unknown) and put an asterisk (*) adjacent to them in a new column. I then clicked on the Key Match’s Shared Matches and reviewed that list – on the right side was the shared cM with each Match. Initially I went from top to bottom of that list and put the shared cM amount in the column under the * and in the row for the match – creating a matrix of sorts. After a few iterations, I limited this to shared cM amounts over about 50cM and highlighted amounts over 90cM. As indicated above, I sometimes found very large cMs, indicating very close relationships – clearly on one particular branch twig in my Tree; and sometimes one Match had a full Tree and the others did not (very useful, bringing Matches with little to no info into play). One vexing Match has a father born the same year as me, so I can assume a 1R relationship (and her 162cM is 2C1R 53% of the time per DNA Painter). AND I note she shares 1883cM with another Match who is highly suspected of having a NPE bio-parent in my Tree) – the clues are adding up.
The method above is also creating a sub-branch, that could very well be from an unknown wife/mother (39P) for whom I have very few Matches so far. In these cases, I’m creating additional * columns for the highest cM Match in that group and looking at their Shared Matches – looking for one of their closer Matches who might have a Tree; or looking for other Shared Matches who might provide Trees or other insights – all in all: looking for a Cluster that might go back to 39P…
As I’m playing with this method, and adding more * columns (creating a matrix), I’m basically identifying all my Matches on my 8P/9M MRCA branch, and subdividing them into sub-branches. This will get me to a good Cluster from Matches back through 8P/9P MRCA to 18P/19P to 38P/39P and ultimately to the 78P/79P MRCA who are parents of my unknown wife/mother: 39P.
Traditional Clustering methods can do this alone, but knowing the cM relationship between the Matches helps a lot.
Clearly I’ll be spending time with this new spreadsheet. I can add new Matches that are close to my key Matches but may be under 50cM, or even at 20cM, with me, but with helpful Trees and/or Unlinked Trees. At any rate, its easy to sort the spreadsheet on an * column, and easily see Matches who should be grouped on a sub-Branch. And, at any time, I can easily use DNAPainter’s WATO tool to focus on likely Branches. It’s a whole lot easier to find a link by building a Match’s small tree back, when I have good intel on the Surnames and geography and timeframes.
ProTools identification of shared cMs between Matches is a strong addition – well worth $10 for a trial month, IMO.
Please feel free to post your own methods of squeezing out more info using this feature of ProTools.
[22CJ] Segment-ology: My Take on Ancestry ProTools TIDBIT; by Jim BARTLETT 20240629